Meituan's Open-Source Multimodal AI Model Tops Benchmarks
Meituan's Open-Source Multimodal AI Model Sets New Benchmark
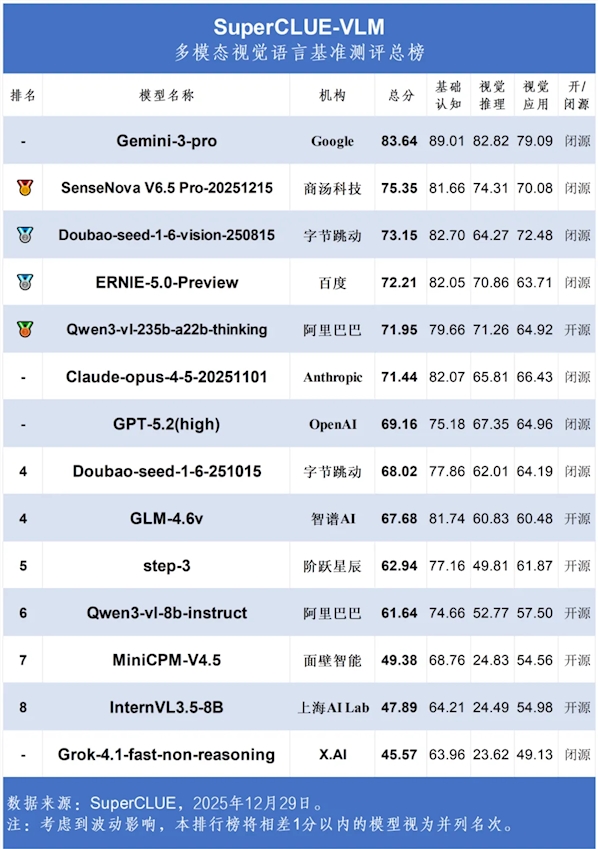
In a significant move for the AI industry, Meituan has unveiled its LongCat-Flash-Omni multimodal large model as an open-source project. The model has already surpassed several closed-source competitors in benchmark tests, achieving a rare "open source as SOTA" (State-of-the-Art) breakthrough.
Technical Breakthroughs
The LongCat-Flash-Omni model stands out for its ability to handle complex cross-modal tasks with precision. For instance, when presented with questions combining physical logic and spatial reasoning—such as describing the motion trajectory of a ball in a hexagonal space—the model can accurately model the scenario and explain the dynamics in natural language.
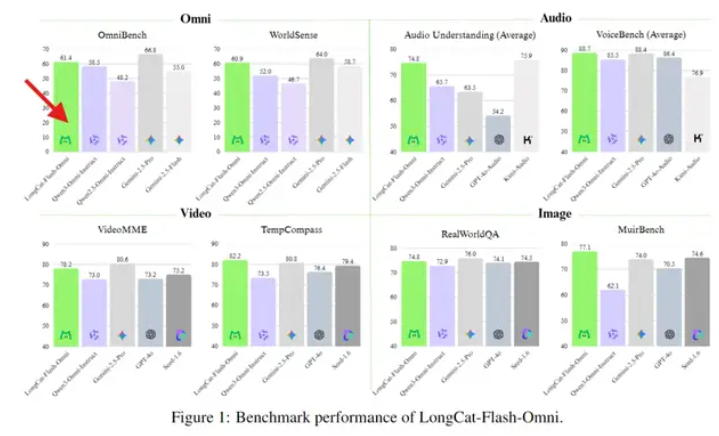
In addition, the model excels in speech recognition, even in high-noise environments, and can extract key information from blurry images or short video clips to generate structured answers.
Innovative Architecture
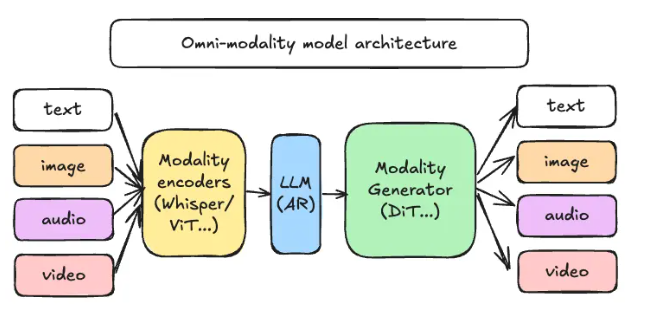
The model's success stems from its end-to-end unified architecture. Unlike traditional multimodal models that process each modality separately, LongCat integrates text, audio, and visual data into a single representation space. This design allows for seamless alignment and reasoning across modalities.
During training, Meituan's team employed a progressive multimodal injection strategy: first solidifying the language foundation, then gradually introducing image, speech, and video data. This approach ensures the model maintains strong language capabilities while improving cross-modal generalization.
Real-Time Performance
One of the most impressive features of LongCat-Flash-Omni is its near-zero latency interaction. Thanks to the Flash inference engine and lightweight design, the model delivers smooth conversations on consumer-grade GPUs. Users interacting with the model via Meituan's app or web version experience minimal delay, achieving a natural "what you ask is what you get" interaction.
Availability and Impact
The model is now freely available on Meituan's platforms. Developers can access the weights through Hugging Face, while ordinary users can test it directly within the application. This move underscores Meituan's confidence in its AI infrastructure and signals its commitment to advancing China's multimodal AI ecosystem.
As AI competition shifts from single-modal accuracy to multimodal collaboration, LongCat-Flash-Omni represents both a technical milestone and a redefinition of application scenarios. Its emergence suggests that China's AI journey is entering a new phase of innovation.
Key Points:
- Open-source SOTA: LongCat-Flash-Omni outperforms closed-source models in benchmarks.
- Unified architecture: Integrates text, audio, and visual data into a single representation space.
- Real-time interaction: Delivers near-zero latency responses on consumer-grade hardware.
- Progressive training: Combines language foundations with gradual multimodal injection.
- Ecosystem boost: Freely available to developers and users, fostering broader adoption.