Maya1 Brings Human-Like Emotion to Open-Source Speech Synthesis
Maya1: The Open-Source Speech Model That Feels Human
Imagine asking your virtual assistant to read tomorrow's weather forecast—not in that familiar robotic monotone, but with the cheerful lilt of a British twenty-something or the dramatic gravitas of a Shakespearean actor. This vision comes closer to reality with Maya1, Maya Research's new open-source text-to-speech model that blends technical sophistication with startling emotional range.
How It Works: More Than Just Words
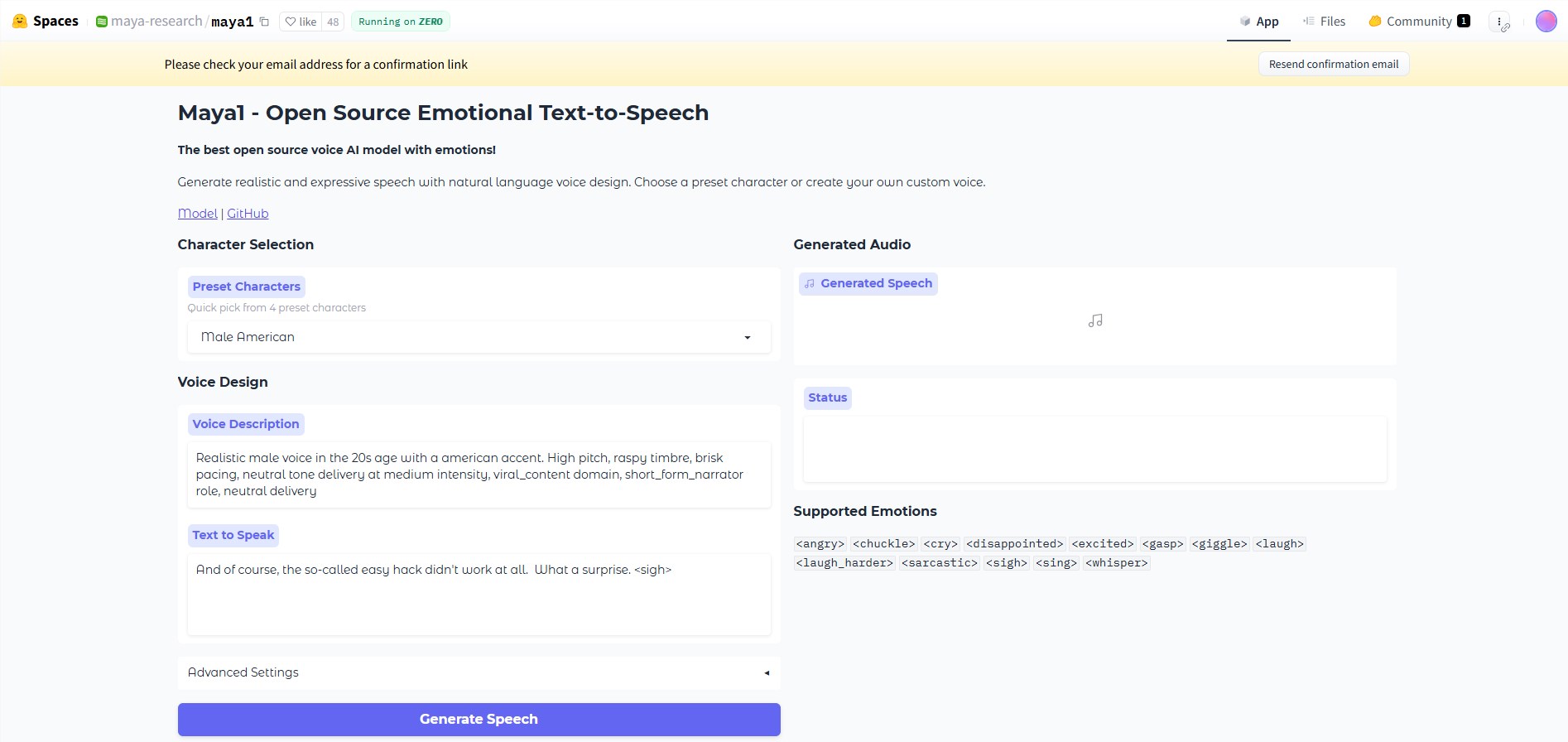
The magic happens through two simple inputs: the text you want spoken and natural language descriptions of how it should sound. Want "a demon character, male voice, low pitch, hoarse tone" reading your horror story? Done. Need an upbeat podcast narrator? Just say "energetic female voice with clear pronunciation."
What sets Maya1 apart are its emotional tags—users can insert cues like , , or `` directly into the text. With over twenty emotions available, these subtle touches transform synthetic speech into something remarkably lifelike.
Technical Muscle Meets Practical Accessibility
Under the hood lies a decoder-only transformer architecture similar to Llama models. But instead of predicting raw waveforms—a computationally expensive process—Maya1 uses SNAC neural audio encoding for efficient processing. This clever approach enables real-time streaming at 24kHz quality on surprisingly modest hardware.
"We've optimized Maya1 to run smoothly on GPUs with just 16GB of memory," explains the development team. While professional setups might use A100 or RTX4090 cards, this lowers barriers for indie game developers and small studios exploring expressive voice synthesis.
The model trained first on vast internet speech datasets before refining its skills on proprietary recordings annotated with precise vocal descriptions and emotions. This two-phase approach helps explain why early adopters report Maya1 outperforming some commercial systems.
Applications That Speak Volumes
The implications span multiple industries:
- Gaming: Dynamic NPC dialogue reacting authentically to player actions
- Podcasting: Consistent narration across episodes without booking voice talent
- Accessibility: More natural reading experiences for visually impaired users
- Education: Historical figures "speaking" in period-appropriate voices
The Apache 2.0 license removes cost barriers while encouraging community improvements—a stark contrast to closed corporate alternatives.
Key Points:
- 🎙️ Expressive Range: Combines text input with descriptive prompts and emotional tags for nuanced speech generation
- ⚡ Real-Time Performance: Streams high-quality audio efficiently on single-GPU setups
- 🔓 Open Ecosystem: Fully open-source under Apache 2.0 with tools supporting easy implementation