Grok4 Outperforms GPT-5 in Reasoning, But at Higher Cost
AI Model Showdown: Performance vs. Cost in Latest Benchmarks
New testing data from the ARC Prize provides crucial insights into the evolving landscape of artificial intelligence, revealing stark differences in performance and operational costs between leading language models. The comprehensive evaluation compared xAI's Grok4 against OpenAI's GPT-5 across multiple benchmarks measuring general reasoning capabilities.
Benchmark Breakdown: Reasoning Capabilities Tested
In the demanding ARC-AGI-2 assessment, which evaluates complex reasoning:
- Grok4 (Thinking) achieved 16% accuracy at $2-$4 per task
- GPT-5 (Advanced) scored 9.9% at just $0.73 per task
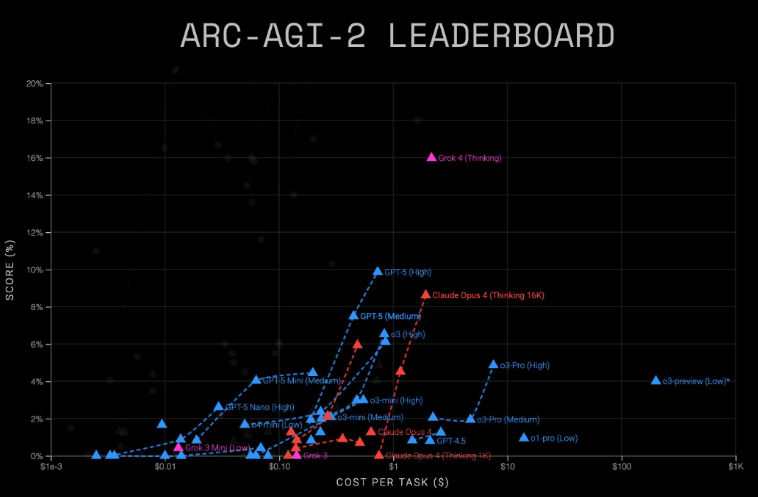 Performance and cost comparison of leading language models on the ARC-AGI benchmark. | Image: ARC-AGI
Performance and cost comparison of leading language models on the ARC-AGI benchmark. | Image: ARC-AGI
The less intensive ARC-AGI-1 test showed:
- Grok4 reached 68% accuracy ($1 per task)
- GPT-5 achieved 65.7% ($0.51 per task)
"While Grok4 demonstrates superior reasoning capabilities, its cost structure makes GPT-5 more economically viable for many applications," noted an ARC Prize spokesperson.
Lightweight Contenders Emerge
The study also evaluated smaller model variants:
| Model | AGI-1 Score | AGI-1 Cost | AGI-2 Score | AGI-2 Cost |
|---|
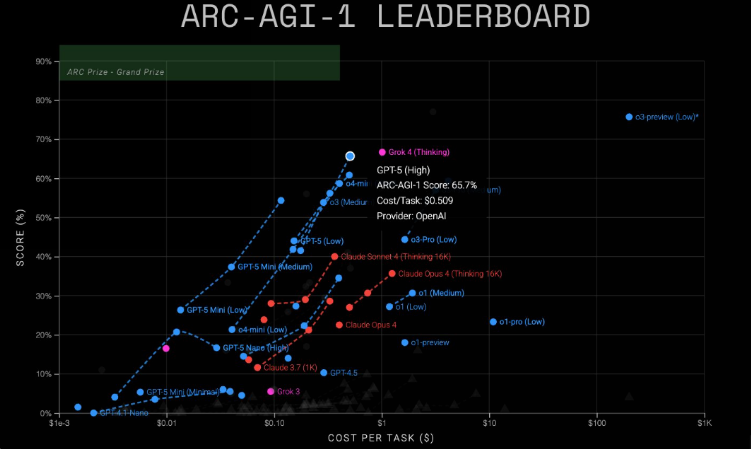 Test results for Grok4, GPT-5, and smaller model variants on the ARC-AGI-1. | Image: ARC Prize
Test results for Grok4, GPT-5, and smaller model variants on the ARC-AGI-1. | Image: ARC Prize
Surprise Performer and Future Tests
The discontinued o3-preview model from December 2024 surprisingly outperformed all current models on AGI-1 with nearly 80% accuracy, though at premium pricing. Meanwhile, development continues on ARC-AGI-3, which will test AI agents in interactive game environments - a challenge where most models still struggle compared to humans.
Key Points:
- Performance lead: Grok4 outperforms GPT-5 in reasoning tasks by significant margins (16% vs 9.9% on AGI-2)
- Cost efficiency: GPT-5 maintains better value proposition across all tests ($0.51 vs $1 on AGI-1)
- Lightweight options: Smaller GPT variants show promise for cost-sensitive applications
- Future benchmarks: New interactive testing environments may reshape performance rankings