Google's Gemini 2.5 Flash Lite Now Fastest Proprietary AI Model
Google Boosts Gemini AI Speed and Efficiency
Google has rolled out significant updates to its Gemini series of large language models (LLMs), with Gemini 2.5 Flash Lite now ranking as the fastest proprietary model available, according to third-party evaluations.
Speed and Performance Gains
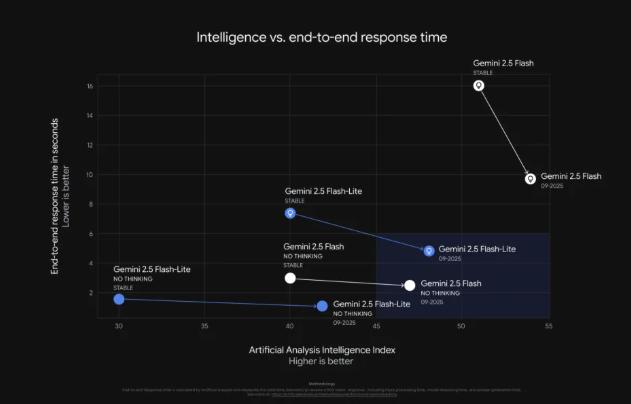
Independent analysis by Artificial Analysis confirms that Gemini 2.5 Flash Lite delivers an impressive 887 tokens per second, marking a 40% speed increase over its predecessor. While this falls short of the 2,000 tokens per second achieved by MBZUAI and G42AI's open-source K2Think model, Google's proprietary offering remains highly competitive.
Cost Efficiency Improvements
The latest updates focus on optimizing both performance and operational costs:
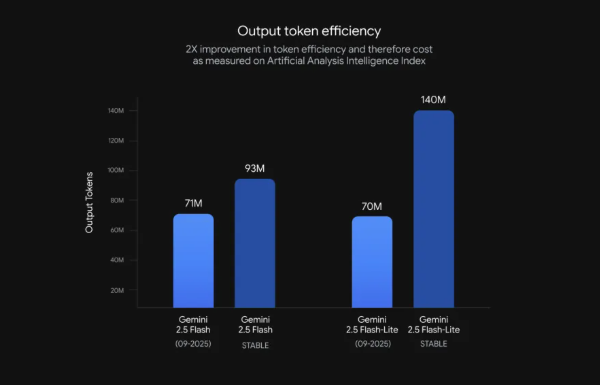
- Flash Lite reduces output tokens by 50%, lowering deployment expenses for high-volume applications.
- Enhanced instruction-following and multimodal capabilities improve response quality.
- Gemini 2.5 Flash excels in complex workflows, scoring 54% on the SWE-Bench Verified benchmark.
Developer-Focused Enhancements
Google introduced new model aliases to simplify integration while maintaining backward compatibility. Independent benchmarks verify measurable improvements across multiple performance metrics.
Voice Assistant Upgrades
The update extends beyond text models:
- Gemini Live, Google's real-time audio model, received reliability improvements for voice applications.
- Enhanced function-call accuracy enables more natural conversational flows.
- Developers can now access these upgrades through a new preview version.
Key Points:
- 🚀 Gemini 2.5 Flash Lite hits 887 tokens/sec – fastest proprietary model available
- 💰 50% token reduction lowers operational costs significantly
- 🗣️ Gemini Live improvements enable more natural voice interactions
- 🔧 Developer-friendly updates include simplified integration options