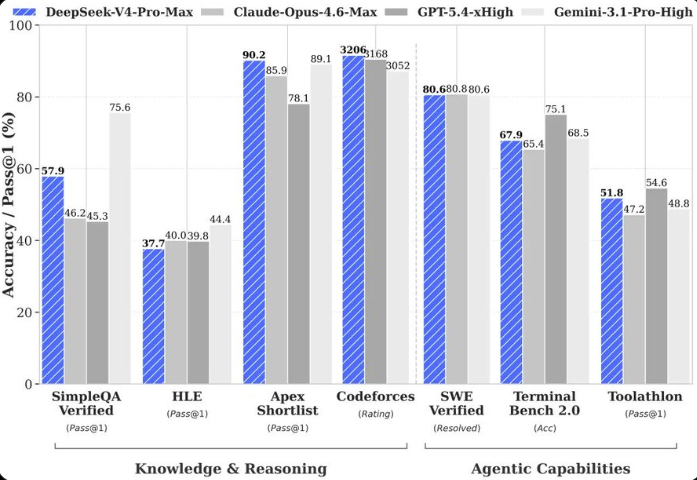
DeepSeek V4 Launches with Two Versions: Flash and Pro
DeepSeek V4: A New Era in AI with Flash and Pro Versions
DeepSeek, a leading name in the AI industry, has just rolled out its latest flagship model, DeepSeek V4. This release isn't just another update—it's a strategic move to address diverse user needs with two specialized versions: Flash and Pro.
Tailored Solutions for Every Need
The new lineup replaces the previous deepseek-chat and deepseek-reasoner models with:
- DeepSeek-V4-Flash: Your go-to for quick responses and everyday tasks. It's all about speed and affordability.
- DeepSeek-V4-Pro: When you need serious brainpower for complex problems, this is the model that delivers.
Both versions support a massive 1M context window and can handle outputs up to 384K tokens. They also come equipped with thinking mode (in most cases), JSON output capabilities, and Tool Calls functionality.
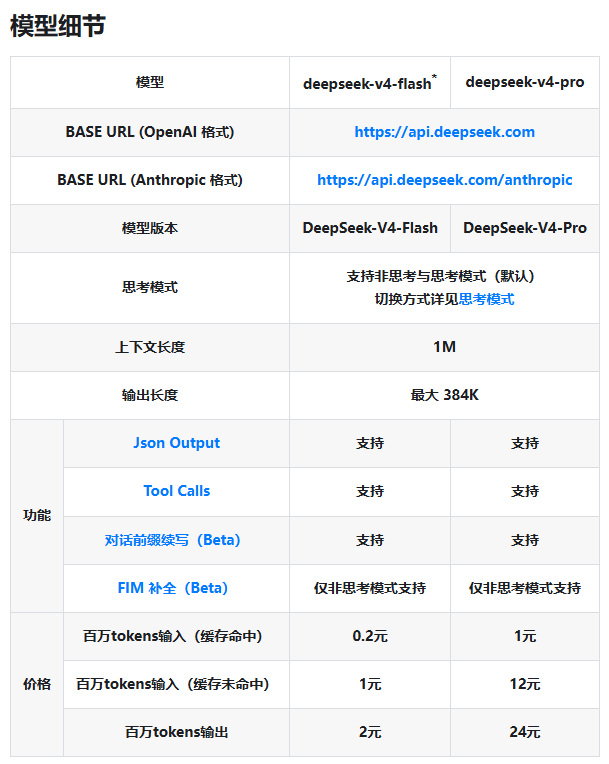
Transparent Pricing That Rewards Smart Usage
DeepSeek's new pricing structure is refreshingly straightforward. Here's the breakdown (per million tokens):
| Model | Input (Cache Hit) | Input (Cache Miss) | Output |
|---|
The significant difference between cache hit and miss prices encourages developers to optimize their caching strategies—a smart way to keep costs down while maintaining performance.
Why This Release Matters
At just ¥1 per million tokens for the Flash version (cache miss scenario), DeepSeek is making top-tier AI technology surprisingly affordable. For businesses needing more muscle, the Pro version offers robust capabilities at competitive rates—perfect for building sophisticated knowledge bases or automated agents.
The company has also made migration easy by allowing direct calls to the new model names (deepseek-v4-flash and deepseek-v4-pro), though they'll eventually phase out the old naming conventions.
For developers ready to dive in, all the technical details are available in the DeepSeek API Official Documentation.
Key Points:
- Two specialized models: Flash for everyday use, Pro for heavy lifting
- Cost-effective pricing: Starts at just ¥0.2 per million tokens (cache hit)
- Smart caching incentives: Significant savings for optimized implementations
- Smooth transition: Direct calls to new model names already supported