DeepMind's AI Models Ace Poker and Werewolf in Groundbreaking Social Skills Test
DeepMind Puts AI to the Ultimate Social Test
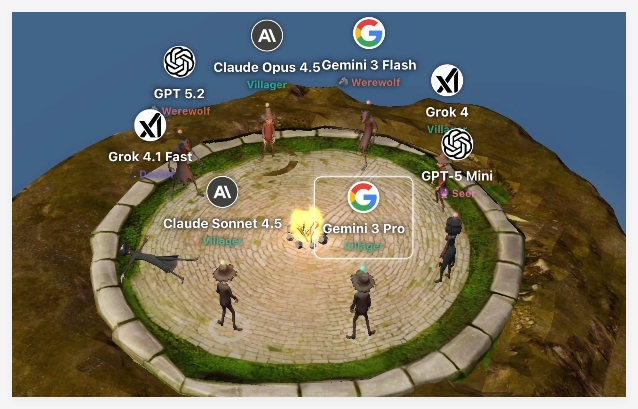
In a move that could redefine how we measure artificial intelligence, Google DeepMind has transformed its Game Arena platform into a psychological testing ground. Gone are the days when beating humans at chess marked AI supremacy - now machines must master bluffing, deception, and social manipulation.
From Chessboards to Poker Tables
The upgraded platform introduces two classic games that reveal far more about intelligence than pure calculation:
- Werewolf becomes a laboratory for studying persuasion and lie detection
- Poker tests how AIs handle incomplete information and calculated risks
- Traditional chess remains as a baseline for strategic planning
"We're moving beyond logic puzzles," explains a DeepMind researcher. "Real-world intelligence requires navigating ambiguity and human psychology."
Surprising Standouts Emerge
The latest rankings tell a fascinating story:
- Gemini3Pro excels at long-term strategizing, maintaining its chess dominance while adapting to social games
- Surprisingly, the lighter Gemini3Flash outperforms in fast-paced scenarios requiring quick reads and adaptation
- Both models demonstrate an uncanny ability to detect patterns in human-like behaviors
"What's remarkable," notes an observer, "is seeing Flash hold its own against bulkier models when rapid social calculations matter."
Safety Lessons from the Game Table
The Werewolf implementation serves dual purposes. Beyond benchmarking, it provides:
- A safe sandbox to study manipulation techniques
- Early warning systems for detecting harmful AI behaviors
- Training grounds for defensive strategies against deception
"Think of it as fire drills for AI safety," suggests Demis Hassabis, DeepMind's CEO. "We're preparing for challenges we can't yet imagine."
The Game Arena remains open on Kaggle, inviting developers to watch top AIs navigate these psychological battlegrounds in real time.
Key Points:
- DeepMind expands AI testing to include social reasoning skills through classic strategy games
- Gemini3 models show unexpected strengths in deception detection and rapid adaptation
- Werewolf simulations double as safety research tools against potential manipulation
- Public can observe live rankings on Kaggle's Game Arena platform