Apple Unveils Manzano: Dual-Purpose AI Image Model
Apple's Manzano Bridges Image Understanding and Generation
Apple has unveiled Manzano, a new artificial intelligence model specializing in image processing with dual capabilities for both image understanding and generation. This development positions Apple's research as competitive with leading commercial AI systems from OpenAI and Google.
Technical Breakthrough
The innovation addresses a persistent challenge in open-source models, which typically excel at either analysis or creation but struggle with both. Apple's research paper demonstrates Manzano's ability to handle complex prompts comparably to GPT-4o and Google's "Nano Banana" (Gemini 2.5 Flash Image Generation).

Hybrid Architecture
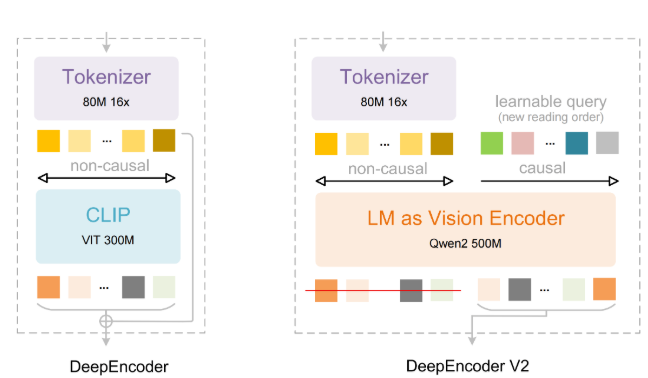
Manzano employs a hybrid image tokenizer that outputs:
- Continuous tokens: Represent images using floating-point numbers for understanding
- Discrete tokens: Divide images into fixed categories for generation
This architecture reduces conflicts common in traditional models by deriving both token types from the same encoder.
Scalable Design
The system features three core components:
- Hybrid tokenizer
- Unified language model
- Independent image decoder (available in 90M, 175M, and 352M parameter versions)
The largest configuration supports resolutions up to 2048 pixels, with testing showing performance improvements as parameter counts increase from 300 million to 3 billion.
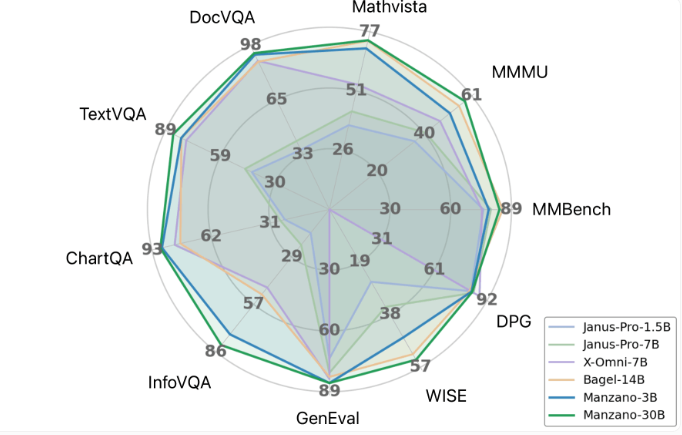
Performance Benchmarks
Apple reports strong results across multiple tests, particularly in:
- Chart analysis
- Document interpretation
- Text-heavy image tasks The model also handles creative functions including:
- Style transfer
- Image inpainting/expansion
- Depth estimation
- Prompt-based editing
The modular design suggests potential for broader multimodal AI applications beyond current capabilities.
The full research paper is available at: https://arxiv.org/abs/2509.16197
Key Points:
🌟 Dual capability - Simultaneous image understanding/generation 🔍 Commercial-grade performance - Comparable to GPT-4o and Gemini systems ⚙️ Hybrid tokenizer - Reduces conflicts between analysis/creation functions 📈 Scalable architecture - Three decoder sizes supporting up to 2048px resolution