Alibaba International Unveils Ovis2.5, Advancing AI Visual and Reasoning Capabilities
Alibaba International Unveils Next-Gen AI Model Ovis2.5
Alibaba International has officially released Ovis2.5, its latest multimodal large model, now available as open-source. This next-generation AI focuses on native resolution visual perception, deep reasoning, and cost-effective scenario design, aiming to push the boundaries of artificial intelligence applications.
Performance and Versions
The model has achieved a comprehensive score of 78.3 on the mainstream multimodal evaluation suite OpenCompass, outperforming many larger models and securing the top spot among open-source models with fewer than 40 billion parameters.
Ovis2.5 comes in two versions:
- Ovis2.5-9B: Optimized for high-performance applications, scoring 78.3 on OpenCompass.
- Ovis2.5-2B: Designed for edge-side and resource-constrained environments, scoring 73.9 while maintaining efficiency.
Architectural Innovations
The development team implemented systematic upgrades across three key areas:
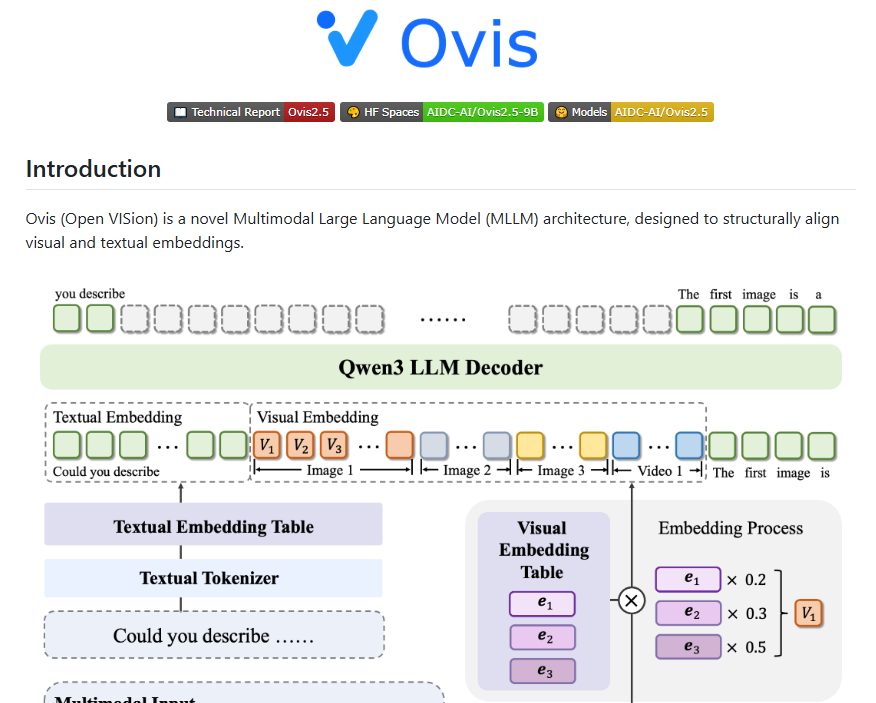
- Model Architecture: Retains the series' structured embedding alignment design, featuring dynamic resolution visual feature extraction and enhanced language processing via Qwen3.
- Training Strategy: Employs a five-stage training plan including visual pre-training and large-scale instruction fine-tuning, with algorithms like DPO and GRPO to boost reasoning capabilities.
- Data Engineering: Increased training data by 50%, with emphasis on visual reasoning, charts, OCR, and Grounding tasks.
Availability and Applications
The code and models are now accessible on platforms including GitHub and Hugging Face, enabling developers worldwide to explore its potential across various AI applications.
Key Points:
- 🚀 SOTA Performance: Scores 78.3 on OpenCompass, leading open-source models under 40B parameters.
- ⚙️ Dual Versions: Ovis2.5-9B for high-power needs; Ovis2.5-2B for edge computing.
- 📈 Enhanced Training: Five-stage strategy with preference alignment algorithms improves reasoning.
- 🔍 Focus Areas: Expanded data targets visual reasoning, OCR, and structural understanding.