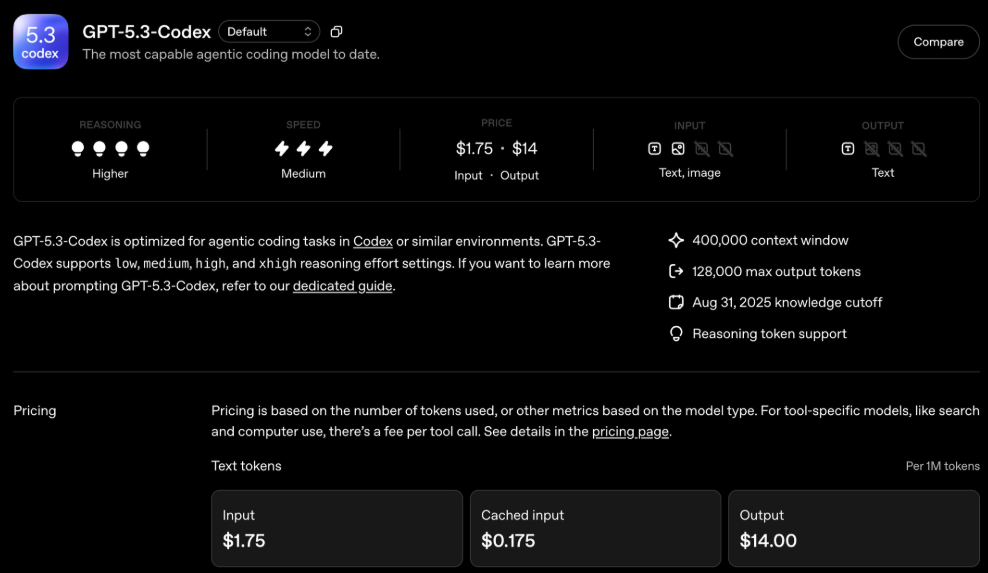
AI Coding Assistants Put to the Test: Who Really Delivers?
AI Coding Assistants Face Reality Check
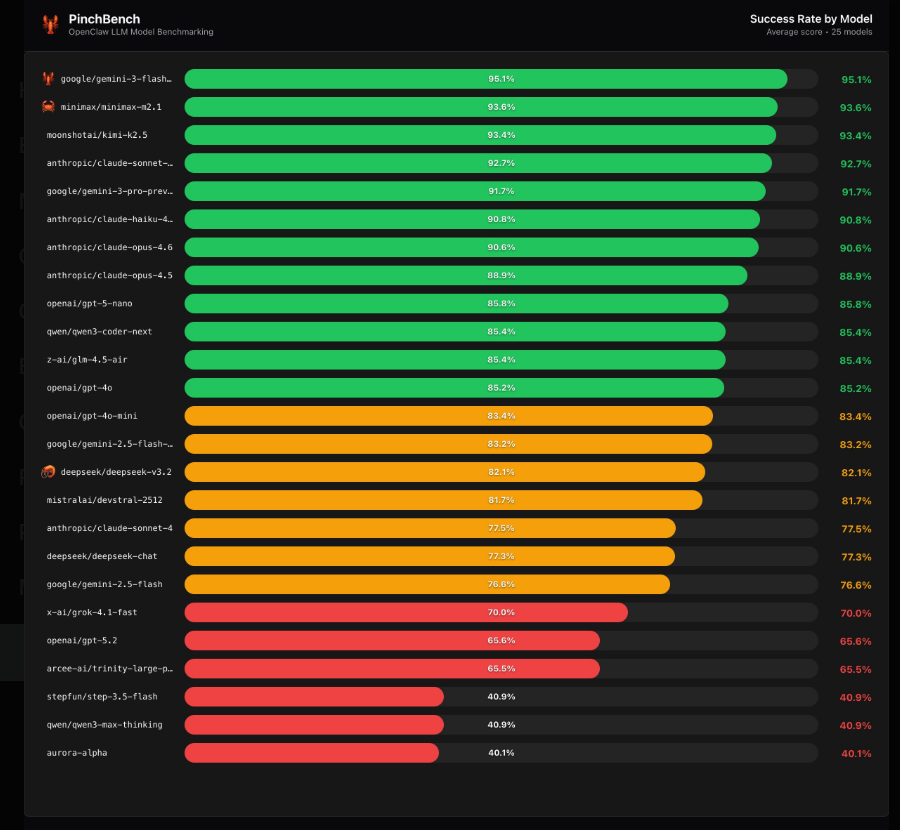
The tech world is buzzing about the newly released OpenClaw rankings, a no-nonsense evaluation that puts AI coding assistants through their paces. Unlike theoretical benchmarks, this test measures how well these tools perform when given actual programming tasks to complete.
How the Tests Work
The OpenClaw framework uses a clever dual-check system: automated code verification combined with AI review. This eliminates human bias while ensuring each model faces equally challenging tasks. "We wanted to create something that reflects real developer needs," explains the team behind the project. "It's not about who can write the fanciest code - it's about who can deliver working solutions."
The Standout Performers
Three models emerged as clear frontrunners:
- Gemini3Flash Preview took top honors with consistently reliable outputs
- MiniMax M2.1 impressed with its handling of complex logic
- Kimi K2.5 rounded out the podium with strong all-around performance
But perhaps the biggest story comes from the Claude family of models, which collectively dominated the middle ranks with success rates above 90%. Their ability to handle multi-step coding challenges suggests particular strength for enterprise applications.
Surprising Struggles
The evaluation delivered some shockers too. Despite its massive parameter count, GPT-5.2 managed only a 65.6% success rate - far below what many would expect from such a prominent model. Meanwhile, DeepSeek V3.2 hovered around average at 82%.
"These results confirm what many developers suspected," notes one industry analyst. "Raw computational power doesn't always translate to practical coding ability."
What This Means for Developers
The OpenClaw rankings provide something rare in the AI space: clear, actionable data about which tools actually work under pressure. For teams choosing coding assistants, these results could mean:
- Better productivity by selecting proven performers
- Fewer debugging headaches from unreliable outputs
- More confidence in implementing AI-assisted workflows
The team plans to update rankings quarterly as models evolve.
Key Points:
- Real-world testing reveals which AI coding assistants deliver functional solutions
- Gemini3Flash leads while Claude models show particular consistency
- Surprise underperformers prove bigger isn't always better
- Practical implications for development teams choosing tools