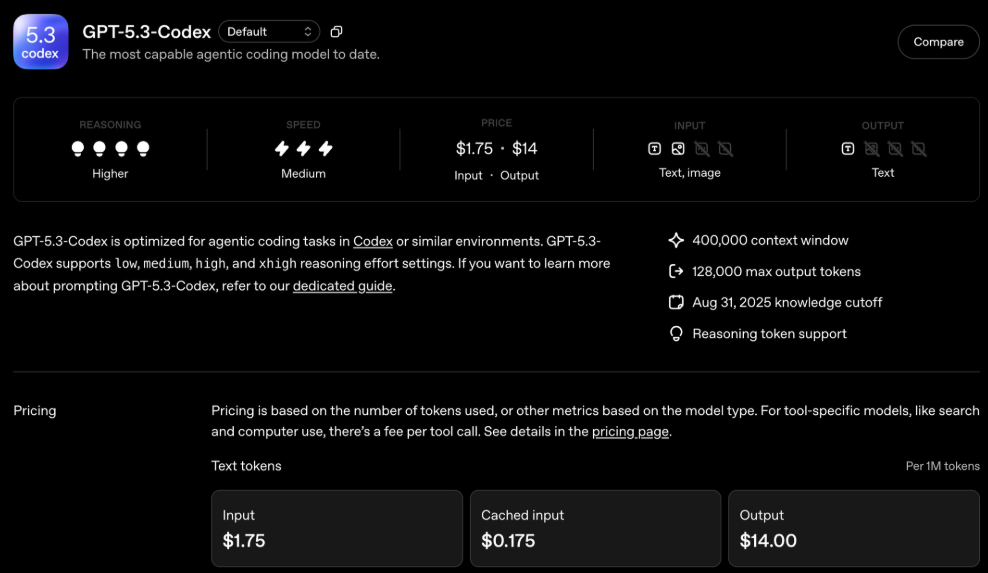
AI Coding Assistants Put to the Test: Who Really Delivers?
Coding Assistants Face Reality Check
The AI development world is buzzing about the newly released OpenClaw evaluation results, which put popular coding assistants through their paces in real-world scenarios. Unlike theoretical benchmarks, these tests measure how well AI models actually perform when tasked with writing functional code.
How the Tests Work
The OpenClaw framework uses automated code checking combined with intelligent review by other language models to score performance objectively. "We wanted to eliminate human bias," explains the team behind the evaluation. "This dual-mechanism approach ensures every model faces identical challenges under equal conditions."
Surprising Standouts
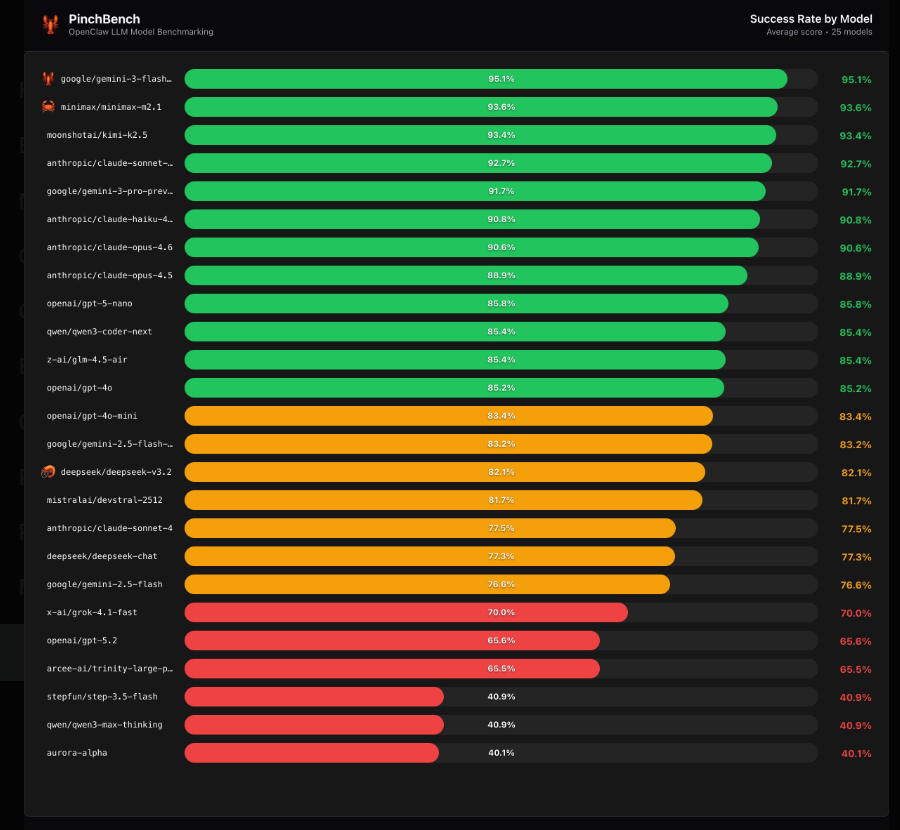
The rankings revealed some unexpected results:
- Gemini3Flash Preview claimed top honors
- MiniMax M2.1 followed closely behind
- Kimi K2.5 rounded out the top three
What really turned heads was the strong showing from Claude's family of models - Sonnet4.5, Haiku4.5, and Opus4.6 all achieved success rates above 90%. "Their performance in complex, multi-step coding tasks was particularly impressive," notes one reviewer.
Established Names Stumble
The evaluation delivered sobering news for some industry heavyweights:
- GPT-5.2 managed only a 65.6% success rate
- DeepSeek V3.2 hovered around 82%
These results challenge conventional wisdom that bigger always means better in AI models. As one developer commented after seeing the rankings: "It's not about how many parameters you have - it's about how well you can actually get work done."
What This Means for Developers
The OpenClaw findings provide valuable guidance for teams choosing coding assistants:
- Consider specialized tools over general-purpose models for coding tasks
- Don't assume bigger names mean better performance
- Test candidates against your specific workflow needs
The full rankings offer concrete data points that go beyond marketing claims - exactly what developers need when making important tooling decisions.
Key Points:
- Claude models dominated with >90% success rates
- Some major players performed below expectations
- Practical execution matters more than theoretical capability
- Developers gain objective data for tool selection