清华UltraRAG 2.1以突破性框架简化AI检索
清华UltraRAG 2.1革新AI检索系统
在人工智能研究的重大飞跃中,清华大学THUNLP实验室与东北大学NEUIR实验室及技术组织OpenBMB、AI9Stars合作发布了UltraRAG 2.1。这一突破性框架是全球首个基于模型上下文协议(MCP)架构的开源多模态检索系统。
简约与精妙的结合
UltraRAG 2.1最突出的特点?其卓越的易用性。研究人员现在无需编写任何代码即可构建复杂的多模态检索系统——只需配置YAML文件即可立即使用。“我们实质上实现了高级AI检索的民主化,”清华大学开发团队的李伟博士解释道。

三大变革性特性
多模态掌控力
文本与图像分离系统的时代已经结束。UltraRAG 2.1的VisRAG Pipeline轻松处理PDF文档,在构建跨模态索引的同时自动提取文本和图表。需要根据描述查找技术图表?或为科学插图生成标题?该系统能无缝处理这些任务。
智能知识管理
该框架集成MinerU技术,可自动处理Word、PDF和Markdown格式文档。想象上传数百篇研究论文后,系统在一夜之间将其组织成可搜索的知识库——这就是UltraRAG为企业环境带来的强大功能。
透明评估体系
与黑盒解决方案不同,UltraRAG提供清晰指标来评估结果的相关性、准确性和流畅度。开发者可获得可操作的见解来优化系统,而非猜测性能问题。
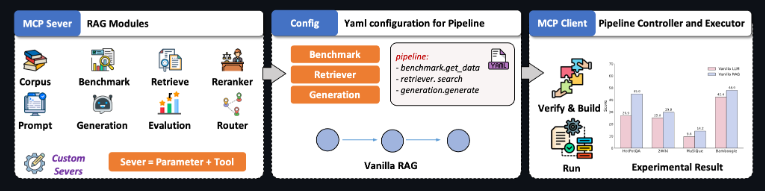
MCP架构优势
其核心秘密在于模型上下文协议架构。传统RAG系统通常像刚性管道,更改一个组件就会破坏另一个组件。MCP将这些组件转化为通过标准化协议通信的模块化“智能代理”。
“这就像从固定铁轨升级到高速公路系统,”东北大学的张教授形象说明,“想更换检索引擎或尝试不同语言模型?使用MCP架构只需编辑配置文件。”
这对企业实施AI解决方案具有深远意义:
- 更快的部署周期
- 更轻松的维护
- 适应新需求的更大灵活性
- 减少对专业编程技能的依赖
展望未来
此次发布标志着机构实施检索增强生成技术的重要转变——从实验原型转向生产就绪系统。
研究团队预计该框架将在处理复杂文档的行业中获得广泛应用:
- 药物研发
- 法律文件分析
- 技术支持系统 -学术文献综述
该框架现已通过开源渠道发布,邀请全球协作进一步扩展其功能。