DeepSeek V3.2-exp 通过稀疏注意力突破性技术大幅降低AI成本
DeepSeek发布革命性架构的AI模型 大幅削减成本
人工智能公司DeepSeek周一宣布在高效AI处理领域取得重大进展,正式推出V3.2-exp实验模型。这一突破性成果的核心在于其专有的稀疏注意力机制,可显著降低长上下文运算的计算成本。

技术创新:稀疏注意力机制解析
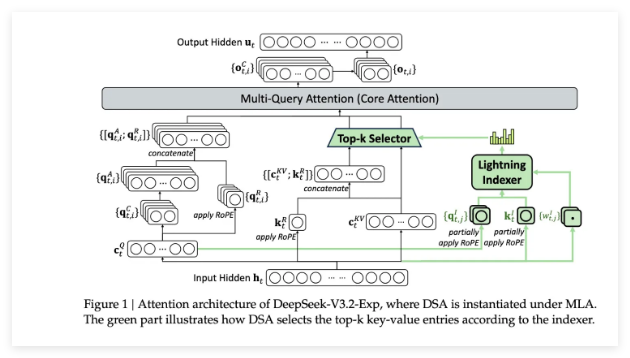
该模型架构包含两项开创性组件:
- 闪电索引器:在处理窗口内优先处理关键上下文片段
- 令牌选择系统:精准识别并仅将必要令牌加载至注意力窗口
这种双系统方法在保持高精度的同时,相比传统Transformer模型大幅降低了服务器负载。
性能表现与行业影响
初期基准测试显示出令人瞩目的结果:
- 长上下文运算的API调用成本降低50%
- 在精简处理的同时保持竞争力精度
- 开源权重特性支持即时行业验证
模型发布包含Hugging Face和GitHub上的完整文档,以及详细阐述技术原理的学术论文。
AI经济学战略意义
DeepSeek的创新专门针对推理成本——即运行已训练AI模型的持续运营开支。这不同于此前主要聚焦训练成本(如R1模型)的降费方案。
此项进展正值:
- 云服务商面临降低AI服务成本的巨大压力
- 企业采用取决于可持续定价模式
- 长上下文应用(法律、研究、编程)亟需高效解决方案
核心要点总结
- 成本削减:初期测试显示最高节省50%费用
- 开放访问:模型权重免费开放验证
- 技术飞跃:新型稀疏注意力架构树立效率新标杆
- 市场时机:直击AI服务经济关键痛点
- 验证路径:行业可立即测试实际性能