DeepSeek的记忆增强:AI模型如何变得更智能
DeepSeek的突破使AI模型更高效
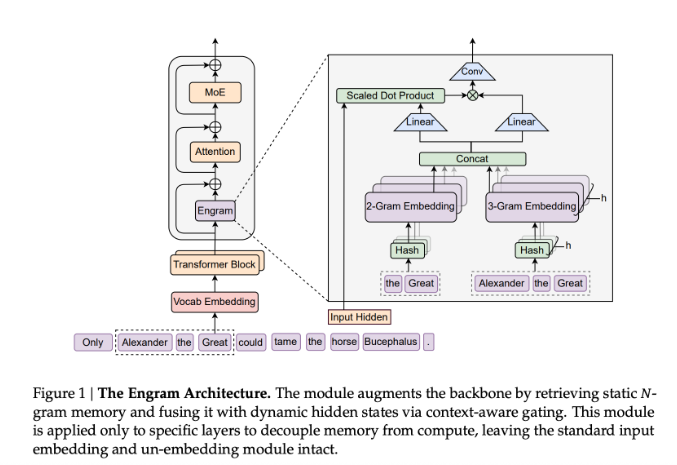
想象一下你的大脑每次做数学时都要重新学习基本的乘法运算。这基本上就是当今AI模型在处理信息时所经历的。DeepSeek的研究团队通过其创新的Engram模块直面了这一低效问题——这是一种帮助人工智能更聪明而非更努力工作的“小抄”。
Engram如何改变游戏规则
这一突破源于认识到当前Transformer模型如何浪费能量。“这些系统不断重复解决相同的简单问题,”研究论文解释道。Engram通过为常用信息和短语创建快速访问的记忆槽来解决这一问题。
与之前试图替换核心系统的方法不同,Engram与现有技术协同工作。可以将其视为在教科书上添加便签而非重写章节。这种优雅的解决方案在保持稳定性的同时提升了性能。
令人印象深刻的实际结果
数据说明了一切:
- 在2620亿数据标记上的测试显示出显著改进
- 仅分配20-25%资源给Engram的模型也看到了明显提升 Engram-27B和Engram-40B模型在多基准测试中持续优于标准版本,包括:
- 常识(MMLU)
- 数学问题(GSM8K)
- 编程挑战
最令人兴奋的或许是Engram处理长文档的能力。当扩展到处理32,768个单词的上下文——大约相当于一部短篇小说——这些增强后的模型在查找特定细节时仍保持了令人印象深刻的准确性。
超越基准的意义
其影响远不止于测试分数:
- 能源效率:减少计算浪费意味着更环保的AI操作
- 可扩展性:系统随模型规模优雅增长
- 实际应用:从法律文件审查到医学研究,更长的上下文理解开启了新的可能性
- 未来发展:这种方法为AI架构改进提供了新途径 DeepSeek团队强调他们只是触及了条件记忆轴所能实现的表面。
关键点:
- 更智能的架构:Engram的O(1)哈希查找提供对常识的即时访问
- 可衡量的提升:27B和40B模型均显示出相对于传统设计的明显优势
- 长文本掌握:增强的记忆能力在处理大量文档时表现出色
- 资源友好:通过消除冗余计算以少做多