机器人视觉领域重大突破:AI现在能更好地理解3D空间
机器人视觉领域重大突破:AI现在能更好地理解3D空间
在机器人技术的重大进展中,研究人员开发了Evo-0——一种创新的视觉语言动作模型,极大提升了人工智能理解和导航三维空间的能力。这项突破性成果来自上海交通大学与剑桥大学的合作研究。
三维理解的挑战
传统视觉语言模型(VLMs)主要依赖2D图像和文本数据进行训练,这限制了它们准确解读现实世界三维环境的能力。这一局限始终是机器人技术发展的障碍,特别是在需要精确空间感知的任务中。
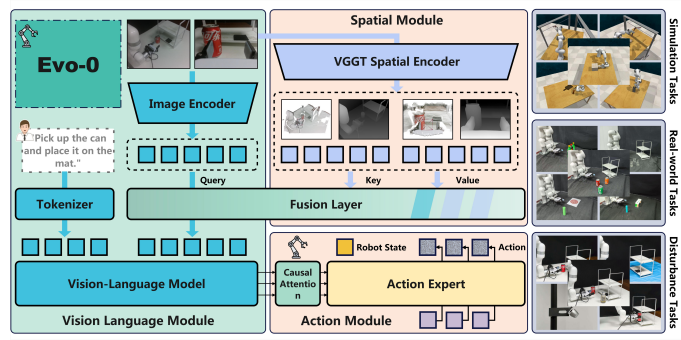
Evo-0的工作原理
Evo-0模型通过整合以下创新方法实现突破:
- 视觉几何基础模型(VGGT):从多视角RGB图像中提取3D结构信息
- t3^D令牌:包含深度上下文和空间关系等几何信息
- 交叉注意力融合模块:将2D视觉令牌与3D令牌相结合
这种架构使机器人无需额外传感器或显式深度输入,就能更好地理解空间布局和物体关系。
性能提升表现
实验结果极具说服力:
- 精细操作任务中成功率比基线模型高出15%
- 在开放VLA基准测试(openvla-oft)上实现31%的提升
- 现实世界空间任务平均提升达28.88%,包括:
- 目标居中定位
- 孔洞插入操作
- 密集抓取作业 该模型尤其擅长理解和控制复杂的空间关系。
实际应用与未来潜力
这项技术的应用前景涵盖多个领域:
- 需要精密操作的工业自动化系统
- 在复杂环境中导航的服务型机器人
- 执行精细作业的自主系统 研究团队强调,Evo-0通过巧妙整合空间信息,为"未来通用机器人策略提供了新的可行路径"。 学术界已注意到这一进展,认为其有望弥合理论AI能力与实际机器人应用之间的鸿沟。
关键要点:
- Evo-0标志着AI理解3D空间能力的重大飞跃
- 该模型的突破无需额外传感器或硬件改造
- 性能提升幅度从15%到31%不等(视任务复杂度而定)
- 工业自动化和服务机器人是主要应用场景
- 技术在保持训练效率的同时提升了部署灵活性