腾讯WeDLM通过扩散模型突破性进展为AI推理加速
腾讯新AI模型实现闪电般快速推理
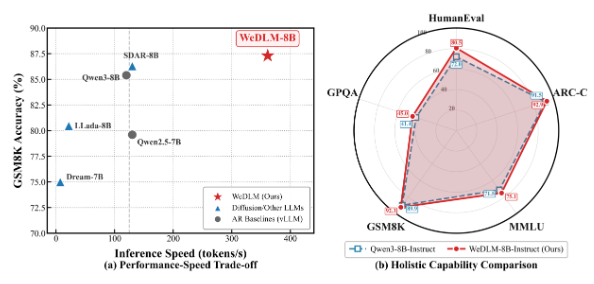
这家科技巨头的微信AI团队通过WeDLM(微信扩散语言模型)开启了语言处理的新可能。这不仅仅是一次渐进式改进——它代表了AI模型处理复杂推理任务方式的根本性转变。
突破速度壁垒
像GPT这样的传统语言模型在处理多个并行请求时经常会遇到瓶颈。WeDLM通过将通常用于图像生成的扩散模型与标准语言处理技术相结合,直面解决了这一问题。秘诀何在?一种创新的"拓扑重排序"方法,同时保持与现有KV缓存技术的兼容性。
"最让我们兴奋的是看到这些理论改进转化为实际性能,"项目首席研究员李伟博士解释道,"在我们的GSM8K数学推理测试中,WeDLM-8B处理解决方案的速度比同类自回归模型快三倍。"
质量与速度兼得
真正的考验在于速度提升的同时不牺牲准确性。基准测试结果令人鼓舞:
- ARC挑战赛:匹配或超越传统模型表现
- MMLU:展现出卓越的理解能力
- Hellaswag:在上下文理解方面表现尤为突出
对于低熵计数任务,速度优势更加显著——有时超过传统方法10倍以上。
实际应用即将到来
这一突破来得正是时候,因为市场对响应式AI系统的需求正在增长:
- 客户服务:对复杂查询的近乎即时响应
- 编程助手:更快的代码生成和故障排除
- 教育科技:数学和科学问题的实时解答 该团队已将模型发布于GitHub,邀请开发者探索其潜力。
关键点:
- ⚡ 极速处理:拓扑重排序使处理速度比现有模型快3-10倍
- 🧠 智能扩展:在高效处理复杂推理任务的同时保持质量
- 💼 商业就绪:特别适合客户服务、编程辅助和教育应用





