NVIDIA开源Audio2Face AI技术,实现实时面部动画生成
NVIDIA通过开源Audio2Face推动面部动画民主化
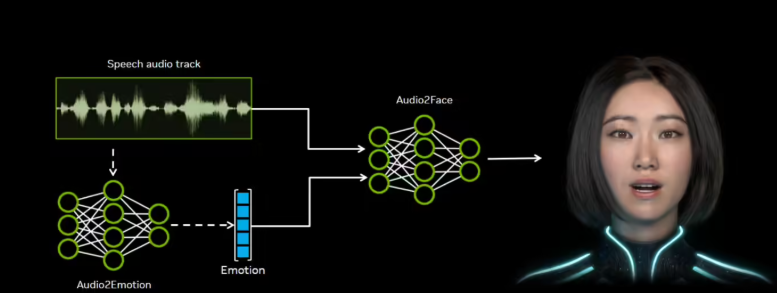
在数字内容创作领域的重要举措中,NVIDIA通过开源许可公开了其Audio2Face生成式AI模型。这项先进技术可将音频输入实时转换为逼真的面部动画,应用范围涵盖游戏开发、电影制作和虚拟客户服务。
技术能力
该系统通过分析音素、语调和语音模式等声学特征,生成与情感表达同步的精确口型动画。NVIDIA此次发布内容包括:
- 完整的软件开发工具包(SDK)
- 用于模型定制的训练框架
- Autodesk Maya和Unreal Engine 5.5+插件
- 回归模型和扩散模型两种架构
该技术支持双操作模式:针对预录制音频的离线渲染,以及面向动态AI角色的实时处理。
行业应用情况
领先的游戏工作室已将Audio2Face集成至生产管线:
- Survios在《异形:火力小队精英》中应用该技术,简化了面部捕捉流程
- Farm51在《切尔诺贝利人2:禁区》中大量使用该技术,显著缩短了动画制作时间
Farm51创新总监Wojciech Pazdur称这项技术是角色动画领域的"革命性突破"。
开发者资源
NVIDIA开发者门户提供的开源包包含:
- 核心动画算法
- 本地执行插件
- 完整的训练框架文档
- 示例实现代码
开发者可使用专有数据集微调模型,创建特定领域的解决方案。
未来影响
此次发布降低了跨行业创建富有表现力的虚拟角色的门槛。随着NVIDIA持续完善其AI工具生态系统,我们有望在娱乐、教育和企业应用中看到更复杂的数字交互方式。
关键要点:
- 🚀 开源可用性: 完整SDK和训练框架已公开发布
- ⏱️ 双重处理模式: 支持预渲染和实时应用场景
- 🎮 已验证的采用案例: 已在主流游戏作品中实施
- 🔧 开发者友好: 包含Unreal等流行引擎的插件
- 💡 可定制性: 模型可通过专有数据进行微调