美团发布LongCat-Flash-Chat:5600亿参数AI模型开启高效新时代
美团发布LongCat-Flash-Chat:AI效率的突破性进展
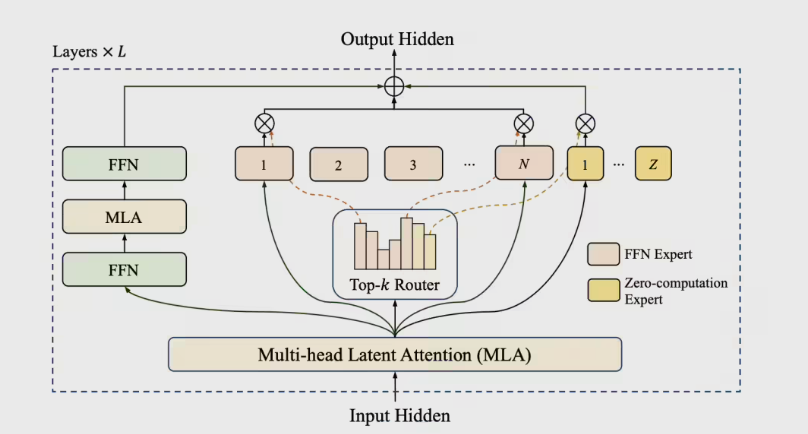
美团正式推出LongCat-Flash-Chat——这款拥有5600亿参数的尖端AI大模型,为计算效率与性能树立新标杆。该开源模型采用创新的混合专家(MoE)架构,通过"零计算专家"机制每token仅激活186亿至313亿参数。
架构创新
模型引入跨层通道设计,显著提升训练与推理并行度。在H800硬件上,LongCat-Flash仅经30天训练即可实现单用户推理每秒100token的惊人速度。其内置的PID控制器动态调整训练过程中的专家偏置,保持平均270亿激活参数以优化算力使用。

卓越的智能体能力
凭借专有的Agentic评估集和多智能体数据生成策略,LongCat-Flash在智能体性能方面表现突出:
- 荣登复杂场景基准测试VitaBench榜首
- 工具使用任务中超越更大规模模型
基准测试统治力
模型在常识评估中全面领先:
- 86.50分于ArenaHard-V2(总排名第二)
- 89.71分于MMLU(语言理解)
- 90.44分于CEval(中文能力)
开源计划
美团开源LongCat-Flash-Chat的决策为开发者提供了研究与应用开发的绝佳机遇。
核心亮点:
- 5600亿参数规模的MoE架构模型
- 每秒100token的推理速度
- **PID控制训练技术保障效率
- 基准测试中顶尖的智能体表现
- 全面开源促进社区发展