Qwen3模型参数更少却实现10倍速度提升
阿里巴巴Qwen3模型掀起AI效率革命
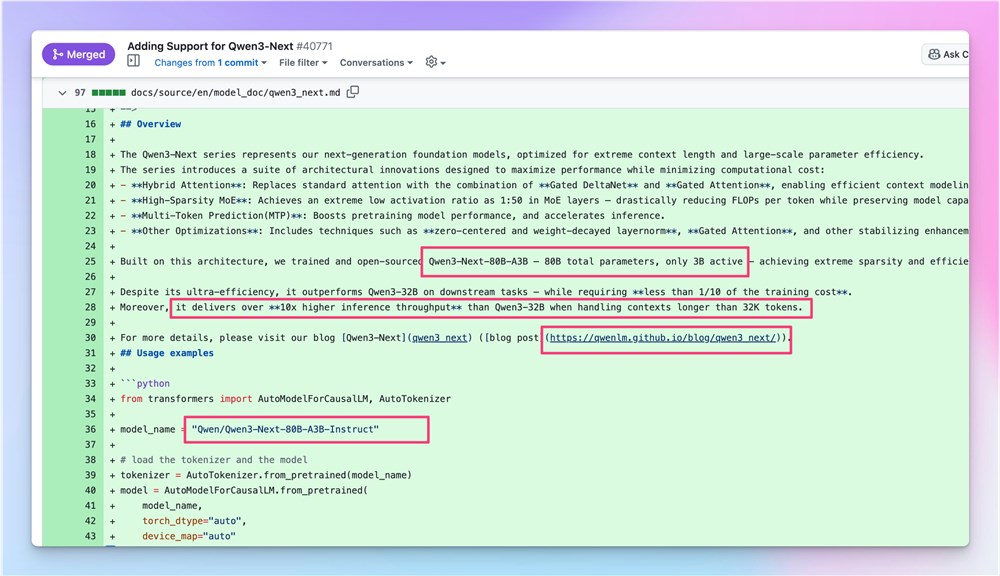
阿里巴巴在大语言模型领域的最新突破让AI研究界兴奋不已。Qwen3-Next-80B-A3B-Instruct模型引入了一种范式转变的方法,在运行时仅激活30亿参数的情况下,就能提供80亿参数级别的能力。
技术突破解析
关键创新在于模型的专家混合(MoE)架构,该架构根据任务需求选择性激活专用组件。这种方法模拟了一个专家团队协作模式,每个任务只有相关专家参与计算,从而显著降低计算开销。
性能提升
早期测试显示出显著改进:
- 相比前代Qwen3-32B模型实现10倍推理速度提升
- 对长上下文序列(32K+ tokens)的优异处理能力
- 在代码生成、数学推理和多语言任务中保持强劲表现
该模型已集成至Hugging Face的Transformers库中,使全球开发者能立即使用这项技术。
成本与可及性优势
效率提升不仅体现在性能上:
- 训练成本降至前代模型的十分之一以下
- 支持在资源受限设备上部署
- 为小型组织利用尖端AI技术开辟可能
行业影响
这一进展不仅仅是渐进式改进:
- 使强大AI模型的获取民主化
- 通过高效计算减少环境影响
- 开启此前受硬件限制的新应用场景
开源发布确保了该技术的广泛采用以及基于此的持续创新。
关键要点:
- MoE革命性架构仅激活必要参数
- 相比前代实现10倍速度飞跃
- 显著降低训练与部署成本
- 完全开源加速生态系统发展
- 有望重塑边缘计算与移动AI应用格局