Meta推出DeepConf技术,在不牺牲准确性的前提下降低LLM成本
Meta发布DeepConf技术实现高效LLM推理
Meta AI与加州大学圣地亚哥分校合作开发了DeepConf(深度置信推理),这项创新技术旨在优化大语言模型(LLM)性能。该技术解决了AI复杂任务中平衡计算成本与推理准确性的行业关键挑战。
基于置信度的创新方法
传统LLM改进策略依赖生成多条推理路径并通过多数表决选择答案。但这种暴力方法消耗大量计算资源,且可能传播低质量推理路径产生的错误。
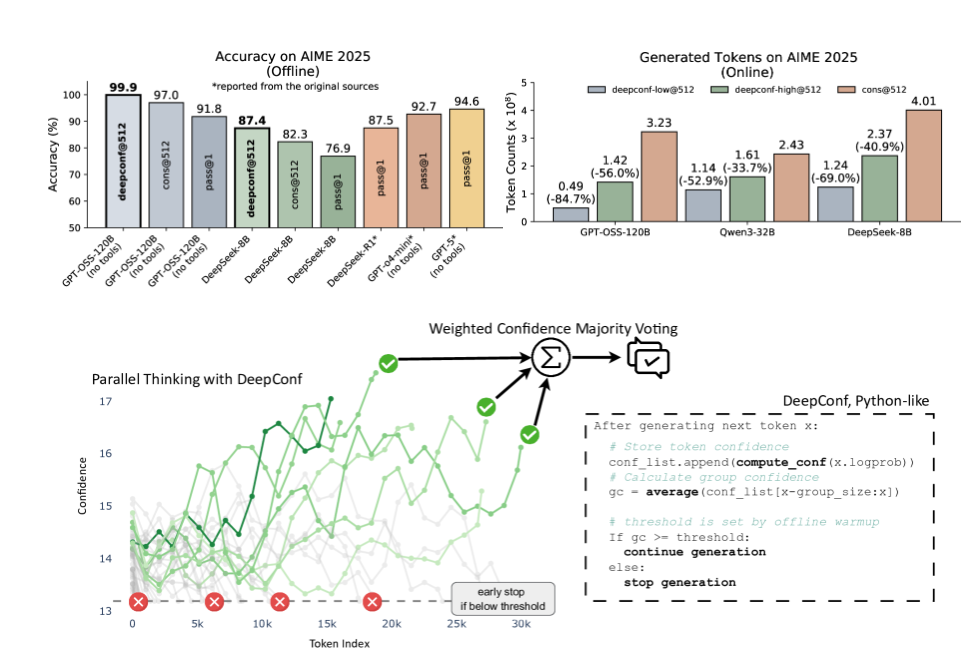
DeepConf的突破性在于通过多重置信度指标动态评估推理质量:
- 群体置信度:跨token片段的平均置信水平
- 尾部置信度:最终阶段推理确定性
- 最低群体置信度:识别脆弱推理点
- 底部10%置信度:聚焦最不确定的片段
双模式运行机制
系统提供两种实施策略:
- 离线思考:首先生成完整推理路径,然后通过基于置信度的投票选择最优解
- 在线思考:实时评估并提前终止低置信度路径以节省资源
已验证的性能提升
在多个模型(包括DeepSeek-8B和GPT-OSS-120B)和挑战性基准测试(AIME、HMMT)中的测试显示出显著成果:
- GPT-OSS-120B在AIME2025上达到99.9%准确率(离线模式)
- 与传统方法相比减少84.7%的生成token量
- DeepSeek-8B在AIME24上实现5.8个百分点的准确率提升(在线模式)
- 在线实施中消耗的token减少77.9%
企业级部署方案
组织可根据运营需求定制DeepConf配置:
| 模式 | 成本降低 | 准确性影响 | 最佳适用场景 |
|---|
该技术无需模型重训练,可与vLLM和TensorRT-LLM等现有推理框架无缝集成。
核心优势
- 🎯 精准优化:用置信度加权路径选择替代统一投票
- ⚡ 资源高效:在减少84.7%token生成的同时保持近乎完美的准确性
- 🛠️ 灵活实施:可选择保守(高精度)或激进(高效率)模式
- 🔌 即插即用:兼容主流推理框架且无需修改模型