美团推出LongCat-Next AI,实现类人类视听能力
美团突破性推出类人类思维的多模态AI
在可能重新定义人工智能与世界交互方式的重大进展中,美团推出了LongCat-Next——一个像人类处理语言那样自然地处理视觉、声音和文本的模型。这项于4月3日发布的技术,标志着与当前通常分开处理不同类型信息的AI系统的显著不同。
突破背后的技术核心
LongCat-Next的核心是创新的DiNA(离散原生自回归)架构。可以将其视为赋予AI所有感官的通用翻译器:
- 全能大脑:无论是阅读文本、分析图像还是理解语音,该模型都使用相同的神经通路,而非独立的专用模块。
- 理解即创造:让它理解段落的同一过程也能生成逼真图像——这种对称性提高了学习效率。
- 像素级压缩:通过名为dNaViT视觉标记器的先进技术,它能将高分辨率图像压缩28倍而不丢失关键细节(如财务报告中的文字)。
"这不只是渐进式改进,"项目首席研究员张伟博士解释道,"我们通过赋予AI类似人类直觉的能力,从根本上改变了它感知现实的方式。"
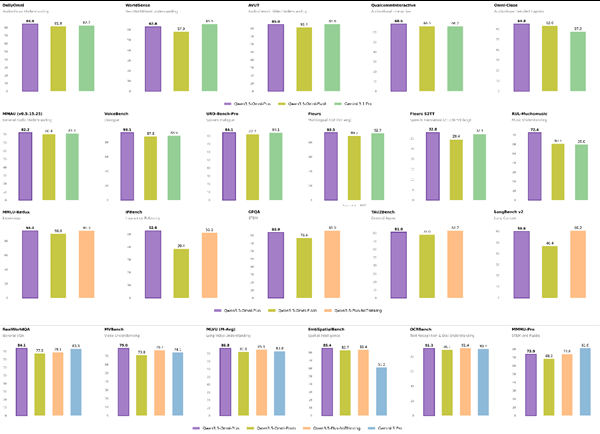
性能实测表现
早期基准测试表明LongCat-Next不仅在理论上令人印象深刻——在实际应用中也表现出色:
- 在密集文本理解上超越专业文档分析模型
- 视觉数学问题解决(MathVista)获得83.1的高分
- 在保持顶尖语言能力(C-Eval 86.80)的同时新增实时语音生成功能
这些结果挑战了AI开发中长期存在的假设。"我们证明了将信息分解为离散单元并不意味着丢失丰富性,"张伟指出,"相反,它能让不同模态相互增强。"
为何这是颠覆性突破
当前大多数AI系统本质上是带有感官附加功能的语言模型。LongCat-Next首次成功将感知能力直接构建到AI基础中:
- 与机器人和虚拟助手的交互更自然
- 更好理解复杂视觉数据(如医学扫描或工程图表)
- 有望实现真正统一的AI系统,而非专业工具集合
团队已开源该模型及其视觉标记器,邀请开发者探索从教育到工业自动化的各种应用场景。
关键要点:
- 原生多模态:通过统一架构处理所有输入类型
- 小巧而强大:先进压缩技术在保持小体积的同时不丢失细节
- 开源可用性:降低实际应用门槛
- 性能领先者:在多项基准测试中超越专业模型