Maya1为开源语音合成注入类人情感
Maya1:拥有情感温度的开源语音模型
想象让虚拟助手播报明日天气预报时——不再使用熟悉的机械单调声,而是带着英国年轻人的欢快语调或莎士比亚戏剧演员的深沉庄重。随着Maya Research新一代开源文本转语音模型Maya1的问世,这个愿景正成为现实。该模型将技术精密性与惊人的情感表现力完美融合。
工作原理:超越文字本身
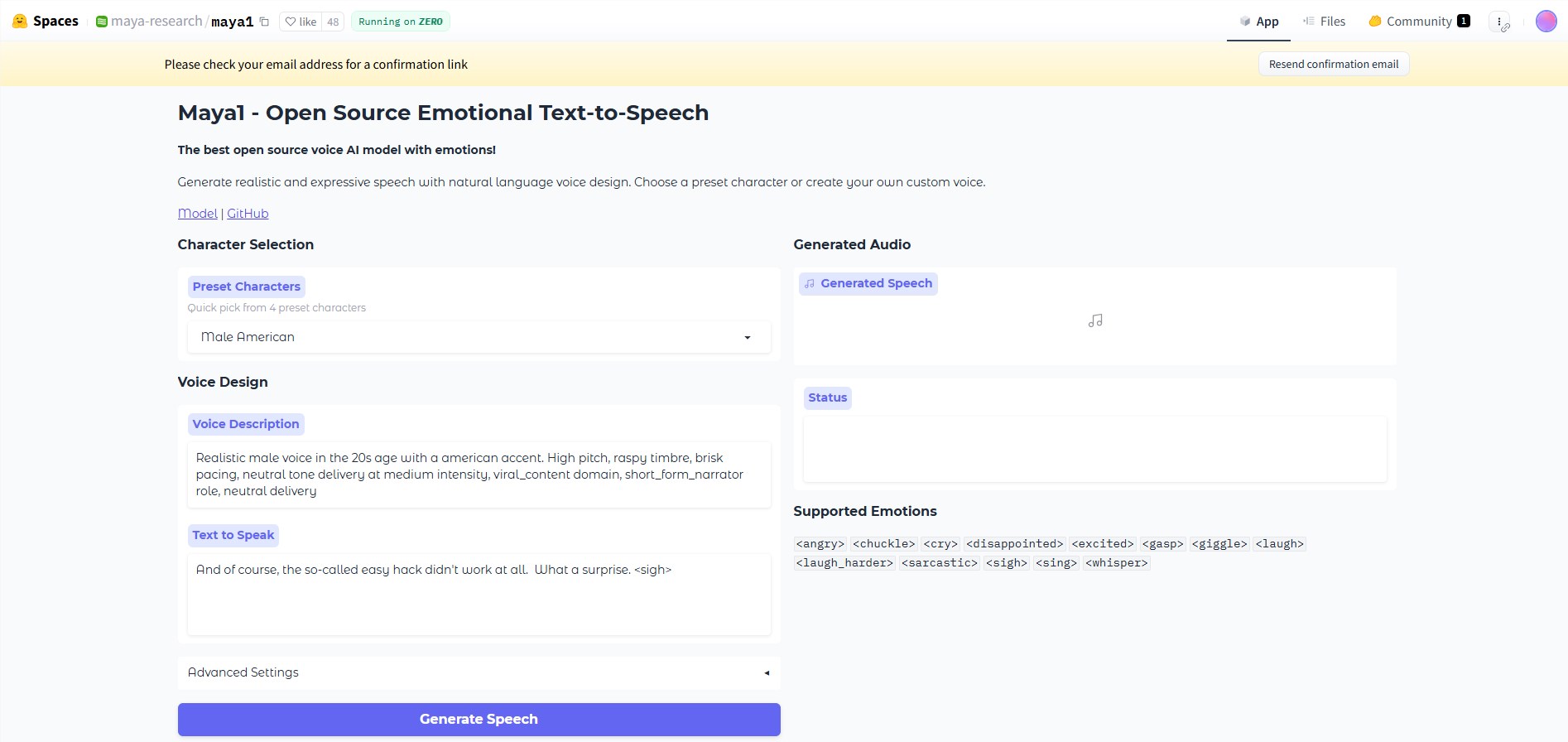
其魔力来自两个简单输入:待转换文本和描述发音风格的自然语言指令。想要「恶魔角色、男声、低音、嘶哑音色」朗读你的恐怖故事?轻松实现。需要活泼的播客旁白?只需输入「发音清晰的活力女声」。
真正让Maya1脱颖而出的是其情感标签——用户可直接在文本中插入(笑)、(叹)或``(耳语)等标记。超过二十种情绪选项的微妙点缀,将合成语音转化为栩栩如生的表达。
技术实力与实用性的平衡
核心采用类似Llama模型的纯解码器Transformer架构。但不同于计算成本高昂的原始波形预测,Maya1使用SNAC神经音频编码实现高效处理。这种巧妙设计使得24kHz高质量音频能在配置普通的硬件上实时流式传输。
开发团队解释:「我们优化了Maya1使其能在仅16GB内存的GPU上流畅运行。」虽然专业环境可能使用A100或RTX4090显卡,但这为探索情感化语音合成的独立游戏开发者和小型工作室降低了门槛。
模型首先在海量互联网语音数据集上进行训练,随后通过标注精确嗓音描述和情感的专有录音进行精调。这种两阶段训练方式解释了为何早期使用者反馈Maya1表现优于部分商业系统。
应用场景潜力无限
其影响将辐射多个领域:
- 游戏:NPC根据玩家行为做出真实动态对话反应
- 播客:无需反复预约配音演员即可保持集间叙事一致性
- 无障碍:为视障用户提供更自然的阅读体验
- 教育:历史人物以符合时代特征的嗓音「亲口」讲述
Apache 2.0许可证消除了成本障碍,同时鼓励社区共同改进——这与封闭的商业替代方案形成鲜明对比。
核心亮点:
- 🎙️ 情感广度:结合文本输入、描述性提示与情感标签实现细腻语音生成
- ⚡ 实时性能:单GPU配置即可高效流式传输高品质音频
- 🔓 开放生态:基于Apache 2.0完全开源并提供易用集成工具