通义实验室发布新一代语音模型,实现类人化响应
通义实验室语音AI突破:会说人话的技术
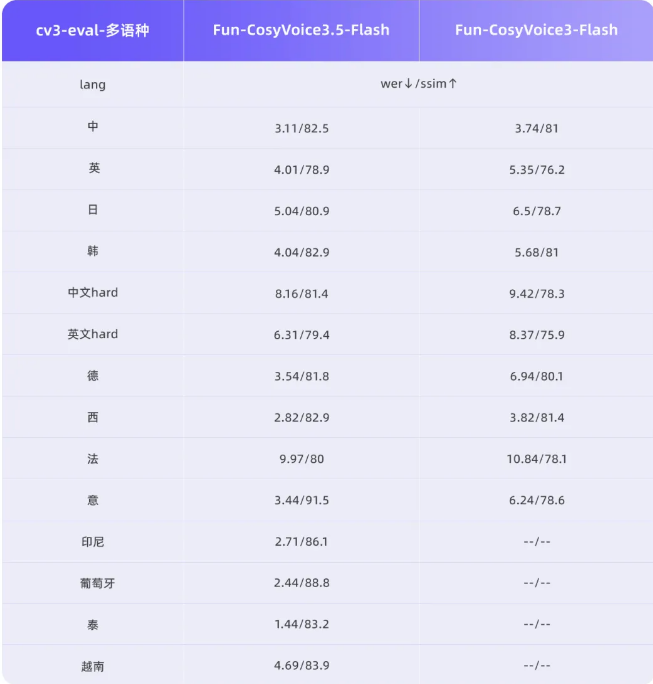
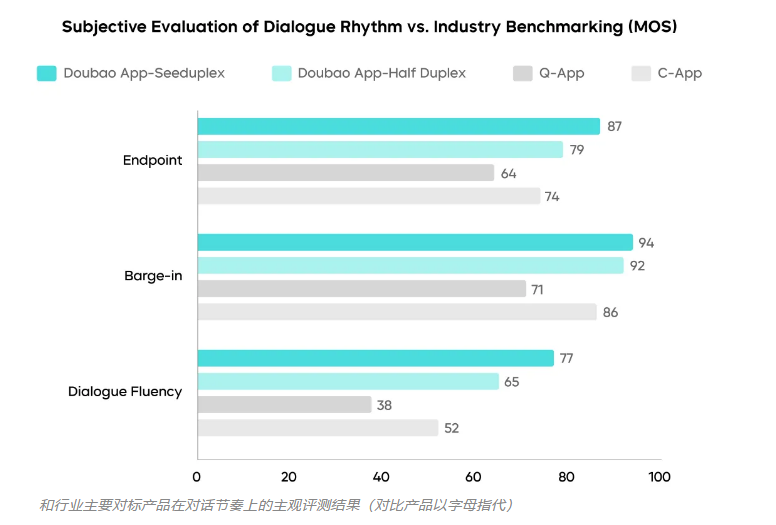
在语音技术的重大进展中,通义实验室发布了Fun-CosyVoice3.5和Fun-AudioGen-VD两款模型,它们能像人类一样自然理解指令。记忆特定命令的时代已经过去——现在你只需告诉系统你的需求。
机器语音中的人性化触感
真正的魔力在于这些模型如何解读请求。想要一个恶棍低声威胁的嗓音?或是愉快的咖啡师接受点单?直接说出来就行。系统会处理其余部分,消除了曾将创作者与强大语音工具隔开的技术术语壁垒。
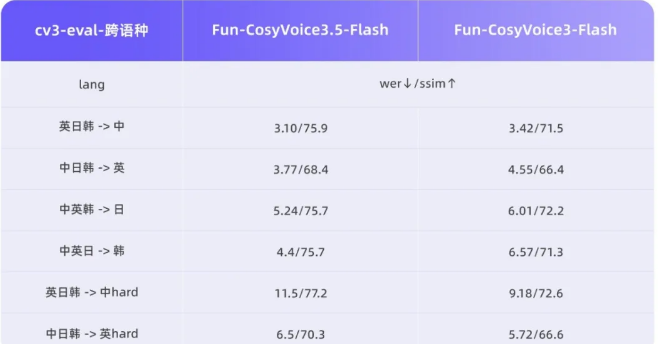
Fun-CosyVoice3.5带来显著升级:
- 新增支持泰语、印尼语等四种语言
- 减少近70%的发音错误
- 大幅降低处理延迟
其秘诀在于结合了名为DiffRO和GRPO的先进强化学习技术,帮助AI捕捉大多数系统会忽略的细微语音模式。
同时,Fun-AudioGen-VD彻底改变了声音设计:
- 根据指令调整性别、情绪甚至房间声学效果
- 从单一嗓音到复杂环境音效皆可创建
- 特别适合游戏环境或电影配音工作流
超越技术圈层的意义
这项技术的影响远不止于炫酷演示。电影工作室可以即时试制角色嗓音;游戏开发者或许能缩短数周制作周期;甚至虚拟助手很快也能以情感智能而非机械精准度回应。
该技术问世之际,市场需求正呈指数级增长——行业分析师预测,随着消费者追求更自然的数字交互,到2028年语音合成市场规模将翻倍。
关键亮点:
- 自然指令取代技术参数
- 生僻词句准确率提升70%
- 响应速度较前代快35%
- 新增语言支持扩展全球可用性
- 情绪范围控制释放创作潜能