蚂蚁集团最新AI模型在多模态技术领域取得突破性进展
蚂蚁集团通过开源发布将多模态AI推向新高度
这一可能重塑AI开发格局的举措中,蚂蚁集团将其先进的Ming-Flash-Omni 2.0模型免费开放给全球开发者。这不仅是常规迭代更新,更代表了机器在多媒介格式理解与创作能力的重大飞跃。
前所未有的视觉、听觉与创作能力
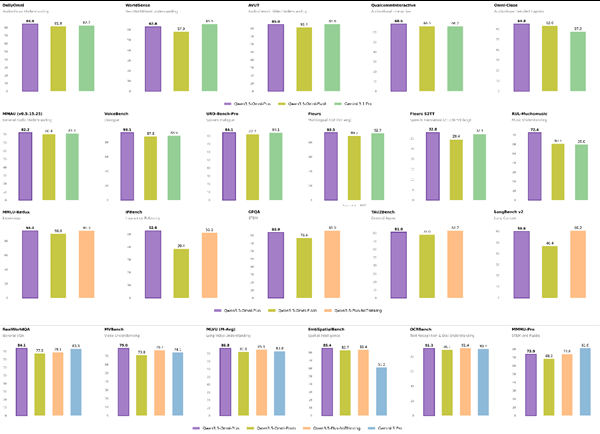
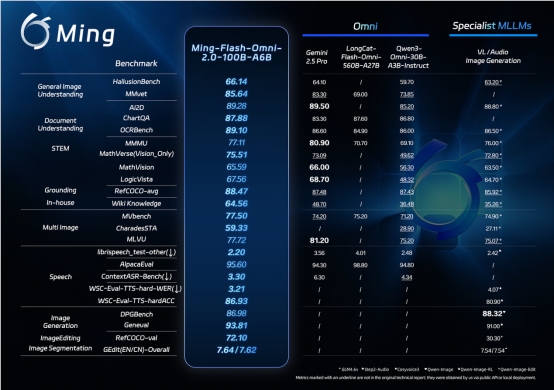
基准测试数据令人印象深刻:Ming-Flash-Omni 2.0在视觉语言处理和音频生成等关键领域甚至超越了谷歌的Gemini 2.5 Pro。但真正使其脱颖而出的是它能同时在单一音轨上处理三种音频元素——语音、音效和音乐的能力。
想象一下描述"雨中的巴黎街道伴随着轻柔爵士乐和说法语的女性声音"就能获得完美同步的输出效果。开发者现在可以获得这种级别的控制力,包括从情感基调到地域口音的各种调整选项。
从专用工具到统一平台
蚂蚁集团百灵模型团队负责人周俊阐释了他们的理念:"我们正在超越专业化与通用化之间的传统取舍。通过Ming-Flash-Omni 2.0,您可以同时获得两者——特定领域的深度能力与灵活的多模态整合。"
此次发布的底层秘密在于Ling-2.0架构。通过海量数据集(我们说的是数十亿个精细标注样本)和优化的训练方法,该团队实现了:
- 视觉精度:能区分近乎相同的动物物种或捕捉复杂工艺细节
- 音频多样性:支持以仅3.1Hz帧率实时生成长达一分钟的片段
- 图像编辑稳定性:即使在改变光照或替换背景时仍能保持真实感
对开发者的意义
此次开源将这些能力转化为所有人都可使用的构建模块。开发者不再需要拼凑单独的视觉、语音和生成任务模型,而是拥有了一个能显著降低集成难度的统一起点。
"我们认为这是在降低门槛,"周俊指出,"以往可能在复杂多模态项目上遇到困难的团队,现在可以专注于创新应用开发而非基础工作。"
模型权重和推理代码已在Hugging Face等平台上线,还可通过蚂蚁的Ling Studio获取更多访问权限。
未来展望
在庆祝这些成就的同时,蚂蚁的研究人员并未止步。接下来的重点包括增强视频理解能力以及突破实时长音频生成的边界——这些领域可能开启更具变革性的应用场景。
The message is clear: multimodal AI is evolving rapidly from specialized tools toward integrated systems that better mirror human perception and creativity. 信息很明确:多模态AI正快速从专用工具发展为更贴近人类感知与创造力的集成系统.
关键要点:
- 开源可用性:Ming-Flash-Omni 2.0现已向所有开发者开放访问权限
- 性能基准:在视觉/音频任务上超越领先模型
- 统一架构:单一框架无缝处理多种媒体类型
- 实际优势:降低多模态项目的开发复杂度
- 未来重点:视频理解与扩展音频生成功能即将推出