美团新AI模型:小巧身材蕴藏强大性能
美团紧凑型AI模型展现超预期性能

在AI模型领域,庞大未必总是优势。传统混合专家(MoE)架构随着专家数量增加常面临收益递减问题。美团LongCat团队通过创新的"嵌入扩展"技术颠覆了这一现状,其LongCat-Flash-Lite模型取得了突破性成果。
重新思考模型扩展方式
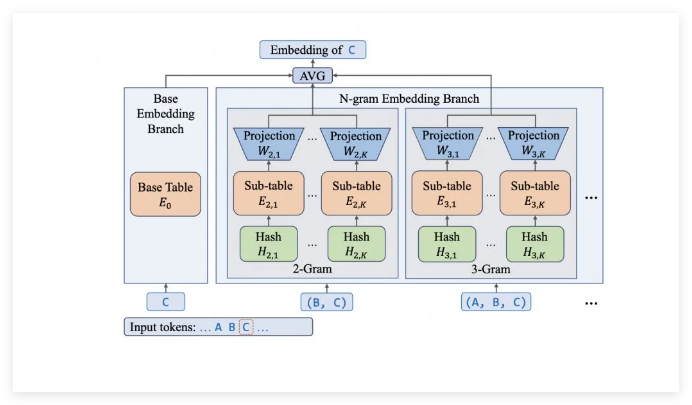
研究人员发现了一个反直觉的突破点:扩展嵌入层的效果竟优于单纯增加专家数量。数据说明一切——虽然完整模型包含685亿参数,但得益于巧妙的N元嵌入层设计,每次推理仅激活29至45亿参数。
技术报告指出:"我们专门为嵌入层分配了超过300亿参数,这使我们能精准捕捉局部语义特征——对识别编程命令等专业语境至关重要。"
全方位工程优化实现高效能
理论优势未必能转化为实际性能。美团通过三大关键优化攻克了这一难题:
- 智能参数分配:近半数(46%)参数用于嵌入层,确保计算量可控增长
- 定制硬件技巧:采用类似KV Cache的专用缓存与融合CUDA内核,大幅降低I/O延迟
- 预测性处理:三步推测性解码方法高效扩展批量处理规模
成效如何?在处理大量输入(4K token)并生成长达1K token输出时,仍能保持每秒500-700token的惊人速度——且支持长达256Ktoken的上下文窗口。
突破基准测试的表现
实测数据证明LongCat-Flash-Lite具备越级挑战能力:
- 在τ²-Bench上擅长电信支持、零售场景等实际应用
- 编程能力突出(SWE-Bench得分54.4%)且命令执行强劲(TerminalBench得分33.75)
- 通用表现不遑多让(MMLU得分85.52),可与Gemini2.5Flash-Lite等更大模型比肩
整套方案——包括权重文件、技术文档及SGLang-FluentLLM推理引擎——现已通过美团LongCat API开放平台开源,并为开发者提供慷慨的每日测试额度。