Google DeepMind新技术让AI在故障中持续学习
Google DeepMind在容错AI训练领域的突破
在人工智能发展这个高风险领域,Google DeepMind直面了一个最令人头疼的问题:当昂贵硬件意外罢工时该怎么办?他们给出的答案——名为Decoupled DiLoCo的智能新架构——可能彻底改变我们训练大型AI模型的方式。
完美同步的问题
传统AI训练方法就像精心编排的芭蕾舞——每个计算单元在梯度更新时必须完美同步。顺利时令人赞叹,但正如所有接触过技术的人所知,完美状态难以持久。一个组件的微小故障就可能导致整个系统停摆。
独立计算岛
Decoupled DiLoCo采用截然不同的方法,创建了工程师称为"计算岛"的结构。想象这些就像处理同一项目不同部分的独立团队。每个岛独立运行,在进行多次本地计算后向中央协调器发送压缩更新。
其精妙之处在于异步性。如果一个岛遇到技术问题(比如TPU过热或网络断开),其他岛可以继续工作。无需等待掉队者,没有系统级超时——只有持续进展。
数据说明重要性
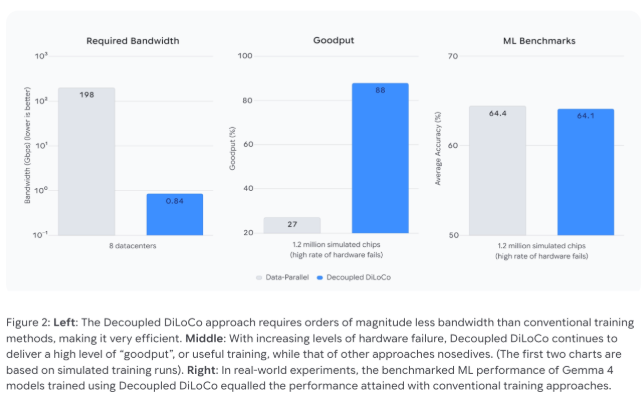
实际效果不言自明:
- 即使频繁出现硬件故障,仍保持88%的利用率(传统方法仅为27%)
- 数据中心间带宽从198 Gbps骤降至不足1 Gbps
- 新旧硬件可以无缝协作
仅带宽降低这一项就具有革命性意义。突然之间,利用现有互联网基础设施而非专用高速连接进行全球AI协作训练成为可能。
令蟑螂都嫉妒的韧性设计
在压力测试(工程师戏称为"混沌工程")中,Decoupled DiLoCo展现出惊人的持续运行能力。即使所有学习单元同时暂时失效,系统也能在恢复后立即从断点继续。
这种韧性还延伸至硬件多样性。不同代际的TPU芯片可以参与同一训练过程,既赋予旧设备新用途,又能在升级过程中平稳过渡。
关键要点:
- 🔄 异步优势:独立计算单元防止单点故障影响整个训练过程
- 🌍 带宽突破:大幅降低的网络需求使全球分布式训练成为现实
- ⚡ 硬件和谐:不同代际的处理单元可高效协作
- 🧠 自愈智能:系统能在不丢失进度的情况下自动从故障中恢复