DeepSeek V4双版本震撼发布:全新价位带来快速与强大的AI体验
DeepSeek V4双版本正式登场
随着DeepSeek V4系列模型的发布,中国AI领域再添亮点。该公司采取巧妙策略推出两个差异化版本——就像在跑车和豪华轿车之间做选择,每种车型都针对不同的驾驶场景而设计。
认识这两个模型
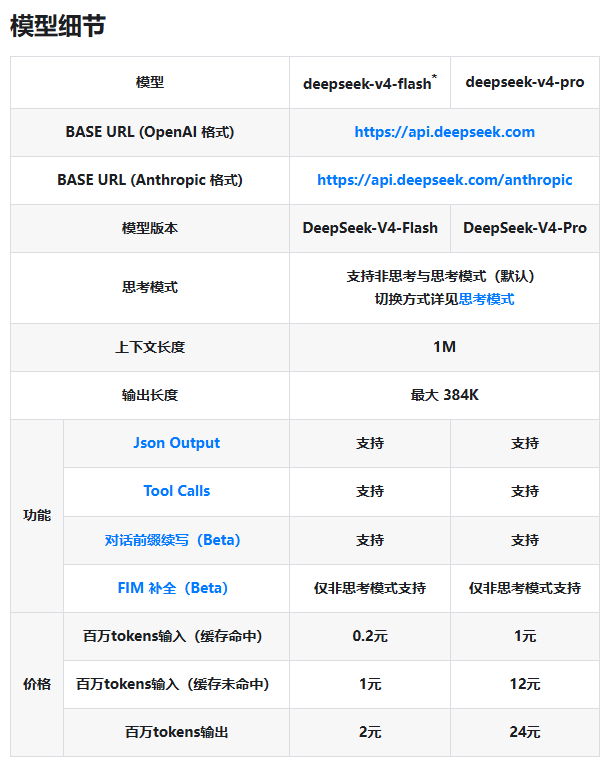
DeepSeek-V4-Flash版本是日常AI任务的理想选择,能快速响应且经济实惠。需要即时聊天回复或基础文本处理?这就是您的性价比之选。
面对更繁重的任务时,DeepSeek-V4-Pro可处理复杂逻辑问题和高强度计算工作。就像从经济舱升级到商务舱,当您需要额外脑力支持时它随时待命。
两款模型均具备令人印象深刻的特性:
- 支持高达100万token的上下文窗口
- 最大输出长度384K token
- JSON输出和工具调用功能
- 思考模式(部分例外)
按需付费的AI定价
定价结构体现了DeepSeek鼓励高效计算的巧妙策略:
| 模型 | 输入(缓存命中) | 输入(缓存未命中) | 输出 |
|---|
缓存与非缓存输入的显著价差并非偶然——这是为优化系统开发的开发者准备的奖励机制。就像自带购物袋享受折扣一样。
定价策略的重要意义
Flash版本仅需每百万token ¥1(无缓存情况下),让更多开发者能够接触强大AI。同时Pro版本为企业构建知识库或自动化代理等复杂系统提供了经济实惠的国产替代方案。
"这种定价结构促进了更智能的系统设计,"一位行业分析师解释道,"通过奖励高效缓存使用,DeepSeek在帮助企业控制成本的同时仍提供顶级性能表现。"
开发者迁移指南
公司提醒旧版模型名称(deepseek-chat和deepseek-reasoner)将逐步停用。开发者应开始迁移至:
deepseek-v4-flash用于标准任务deepseek-v4-pro用于思考模式应用
完整API文档提供了无缝迁移指导。
核心要点:
- 双模型战略同时覆盖轻量级和重型AI需求
- 创新定价奖励高效缓存实践
- Flash版本以每百万token ¥1的亲民价格提供入门机会
- Pro版本为复杂应用场景提供高级能力
- 过渡期已为现有实施方案启动