全球AI对决:海外模型领先,中国选手紧追不舍
中文AI现状:竞争激烈的格局
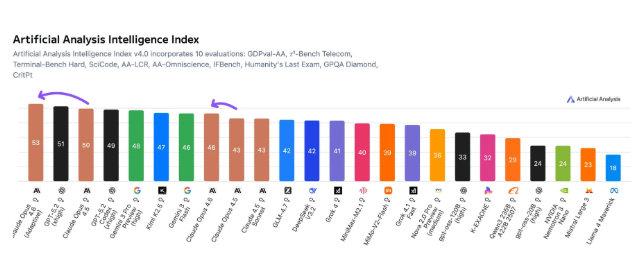
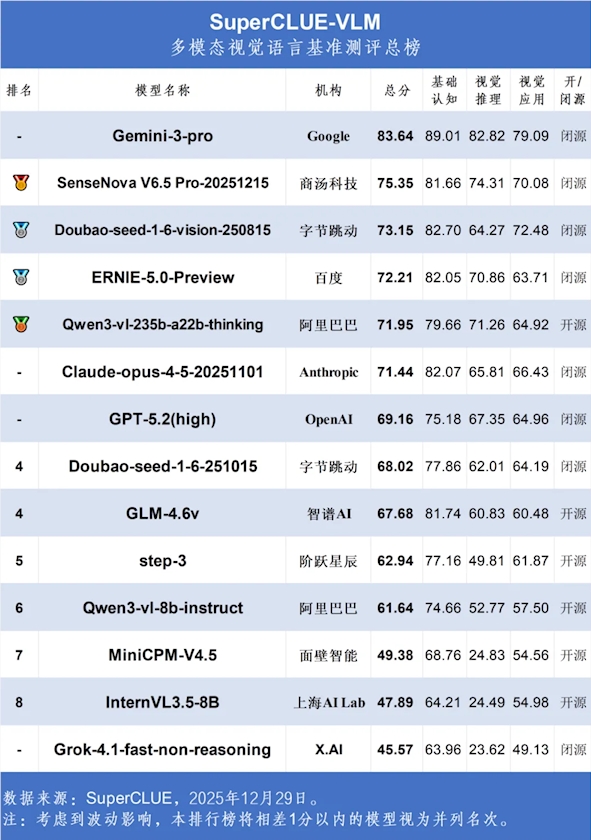
SuperCLUE最新基准测试结果描绘了全球AI竞赛的动态图景。这项2025年评估对23个主流语言模型的六大核心能力进行了测评,结果显示海外模型保持领先的同时,中国替代品展现出惊人进步。
顶尖表现者
Anthropic的Claude-Opus-4.5-Reasoning以68.25分的成绩成为明显赢家,其推理能力尤为突出。紧随其后的是谷歌的Gemini-3-Pro-Preview(65.59分)和OpenAI的GPT-5.2(64.32分),延续了西方科技巨头在该领域的传统优势。
"令人惊讶的不是这些模型的优异表现",AI研究员李伟博士指出,"而是部分中国模型正在逼近它们的水平"。
国内挑战者崛起
真正的亮点或许是中国加速的进步步伐。两款国产模型跻身第一梯队:
- Kimi-K2.5-Thinking(61.50分)总体排名第四,同时在代码生成领域以53.33分的出色表现独占鳌头
- Qwen3-Max-Thinking(60.61分)在数学推理上与谷歌产品并列80.87分——这是AI系统传统薄弱环节
这些结果表明中国开发者正在从追赶者转变为特定领域的真正竞争者。
专精胜过全能?
评估揭示了一个有趣趋势:虽然综合性能仍属海外模型占优,但国产替代品在针对性应用中表现卓越:
- 代码生成:Kimi-K2.5-Thinking大幅领先
- 数学推理:Qwen3-Max-Thinking比肩谷歌最优产品
- 科学理解:多款中国模型显示快速提升
这种专精策略或许解释了国内开发者如何在资源差距下仍能缩小距离。
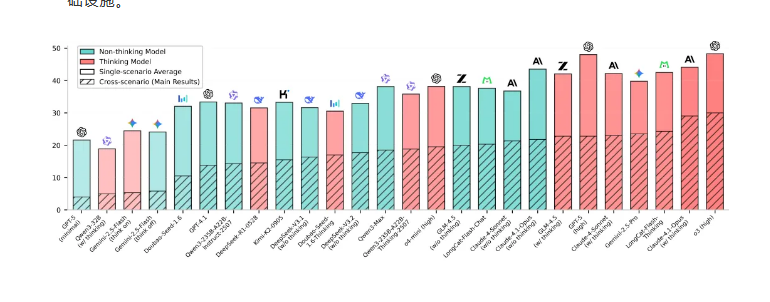
开源优势显现
中国开源模型展现出特殊优势,在该类别前五名中占据四席。这表明中国活跃的开源社区可能成为未来AI发展的重要因子。
"我们看到真正的创新正来自中国的开源生态系统",斯坦福AI研究员Mark Chen观察指出,"他们的协作模式似乎正在收获回报"。
核心要点:
- 海外优势持续:Claude-Opus-4.5-Reasoning领跑总榜
- 中国进步加速:两款国产模型闯入前六
- 专精策略见效:本土模型在编程与数学任务中表现出色
- 开源生态繁荣:中国社区展现强大协作开发能力
- 差距逐步缩小:结果预示未来几年竞争将更趋激烈