美团推出VitaBench:AI智能体评估新标准
美团龙猫团队推出VitaBench:AI智能体评估新标准
美团龙猫研究团队正式发布VitaBench综合基准测试框架,专门用于评估智能体在现实生活多交互任务中的表现。该框架重点针对外卖送餐、餐厅就餐、旅行规划等高频率应用场景。
解决现实世界AI挑战
当前AI系统在复杂场景中表现出明显局限性。据龙猫团队研究显示,即使是领先的推理模型在跨场景任务中的成功率也低于30%。VitaBench旨在弥合实验室表现与实际应用需求之间的差距。
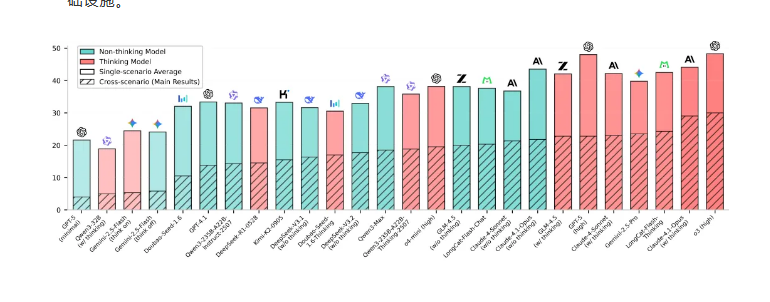
全方位评估框架
VitaBench核心特性包括:
- 66种交互工具模拟真实世界服务
- 购票、餐厅预订等复杂任务模拟
- 三维度评估标准:
- 推理复杂度:衡量信息整合需求与观察空间大小
- 工具复杂度:评估依赖关系与调用链长度
- 交互复杂度:检验多轮对话能力
该基准采用两阶段构建流程,既确保任务多样性,又避免传统文档式评估方法的局限。

开源可用性
团队通过以下渠道向研究社区全面开放VitaBench:
- 含说明文档的官方项目主页
- 包含全部代码的GitHub仓库
- Hugging Face数据集托管
- 追踪性能指标的公开排行榜
核心要点:
- VitaBench从三个关键维度评估AI智能体
- 现有系统在复杂任务中成功率不足30% 该框架专注于超越学术基准的现实世界适用性 项目现已实现全面开源供社区采用

