Claude Opus 4.6加冕AI王座,但能守得住吗?
Claude Opus 4.6在最新AI基准测试中完胜GPT-5.2
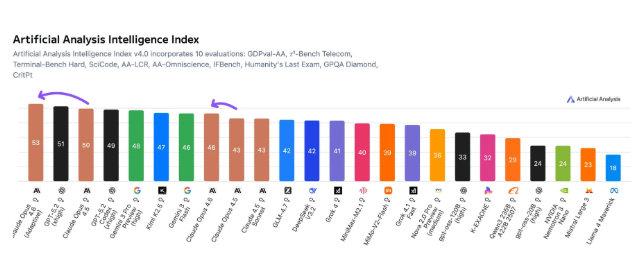
人工智能领域格局变得更加精彩。Anthropic的Claude Opus 4.6在权威的Artificial Analysis Intelligence Index中拔得头筹,在多项高难度测试中表现突出。
胜者诞生
在评估编程到科学推理等十项能力的综合测试中,Opus 4.6尤其在三方面表现卓越:
- 代理任务处理(管理复杂的多步骤流程)
- 终端编程(编写和调试代码)
- 物理研究(解决复杂科学问题)
测试结果揭示了一个有趣的效率优势:虽然Opus 4.6处理了约5800万输出token(是其前代的两倍),但仍远低于GPT-5.2惊人的1.3亿token消耗量。
卓越的代价
卓越性能需要付出真金白银的代价:
- Opus 4.6运行成本:每次测试2,486美元
- GPT-5.2运行成本:每次测试2,304美元
多出的182美元带来了显著更高的效率,但这是否能转化为实际价值取决于具体使用场景。
该模型目前可通过Claude.ai及包括Google Vertex和AWS Bedrock在内的主流云平台获取,方便开发者和企业使用。
竞争从未停歇
OpenAI并未坐以待毙:
- 他们的新编程工具Codex 5.3已进入测试阶段
- 早期迹象表明它可能在编码相关任务中占据主导
- 行业分析师预测完整基准结果公布后它可能重夺榜首
AI霸主之争持续加速,每次技术突破都会迅速被竞争对手追赶或超越。
对用户意味着什么
对企业和开发者而言:
- 当下,Opus 4.6为复杂任务提供更优性能
- 长期来看,所有主要参与者都将快速迭代
- 模型选择越来越取决于具体需求而非原始排名
唯一可以确定的是?这场技术军备竞赛丝毫没有放缓迹象。
关键要点:
- 🏆 Claude Opus 4.6领跑当前AI基准测试
- ⚡ 数据处理效率高于GPT-5.2
- 💰 运行成本略高
- ⏳ OpenAI的Codex 5.3可能很快会挑战榜首地位