Gemini领跑全球AI视觉竞赛,中国模型崭露头角
AI视觉霸权争夺战升温
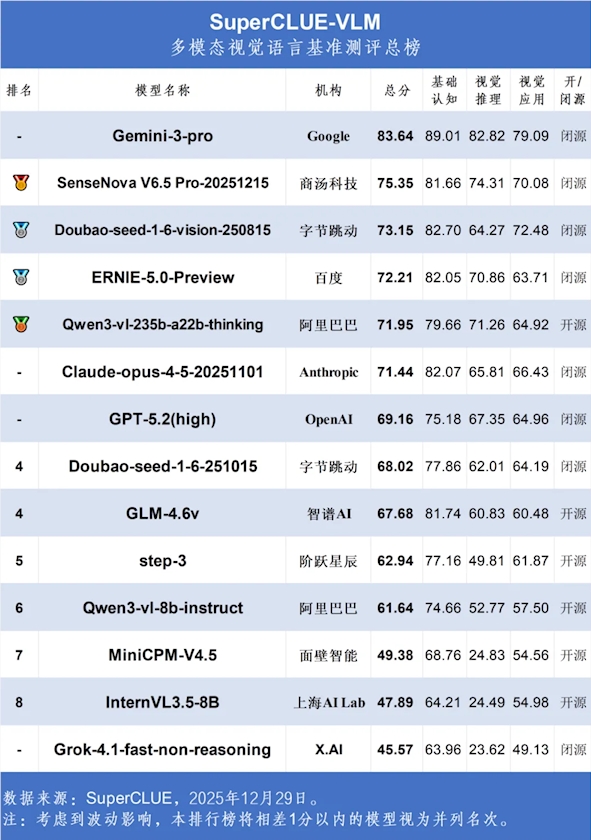
最新的SuperCLUE-VLM12基准测试描绘出当今多模态AI领域的精彩图景。谷歌Gemini-3-pro不仅领跑全场——更以83.64分的统治级表现全面改写各项评估标准。
国内挑战者崛起
本次竞赛特别引人注目的是中国模型的强劲表现。商汤科技的SenseNova V6.5Pro以75.35分夺得亚军,在视觉推理任务中展现特殊优势;字节跳动的抖音视觉版则以73.15分跻身前三,甚至在基础认知测试中超越多个国际竞争对手。
"这些结果印证了中国在计算机视觉技术领域日益增长的实力",清华大学AI研究员李伟博士指出,"三年前我们根本看不到国产模型能达到这种竞争水平"。
意外与突破
本次基准测试呈现多个重要动态:
- 开源里程碑:阿里巴巴的Qwen3-vl成为首个突破70分大关的开源模型(70.89分),为开发者社区提供强大的视觉分析能力
- 老牌选手失利:Anthropic的Claude-opus-4-5仅获71.44分,而OpenAI的GPT-5.2(高级版)69.16分的表现更是远低于行业预期
- 百度稳守阵地:ERNIE-5.0-Preview保持第五名的成绩,延续中国模型的强势表现
对AI发展的启示
结果表明我们正在进入新阶段: 1) 视觉理解能力正成为区分模型的关键要素 2) 专有解决方案与开源方案之间的差距正在缩小 3) AI领域的传统实力排名未必适用于视觉能力评估
"我们看到专业化趋势正在形成",MIT教授Alan Chen解释道,"某些优化文本处理的模型在视觉任务中表现挣扎,而像Gemini这样明显优先多模态训练的模型则表现出色"。
核心要点:
- 全球领跑者:Gemini-3-pro在基础认知(84.2)、视觉推理(83.1)和应用(83.6)三大领域均获最高分
- 中国进步:两款国产模型现已跻身全球视觉基准测试前三强
- 开源进展:Qwen3-vl为社区开发的视觉模型开辟新天地
- 格局变迁:GPT等传统领军者在视觉任务中显现意外短板