苹果发布Manzano:兼具图像理解与生成能力的双用途AI模型
苹果Manzano桥接图像理解与生成
苹果发布了Manzano——一个专注于图像处理的新型人工智能模型,兼具图像理解和生成双重能力。这一进展使苹果的研究成果与OpenAI和谷歌的领先商业AI系统形成竞争。
技术突破
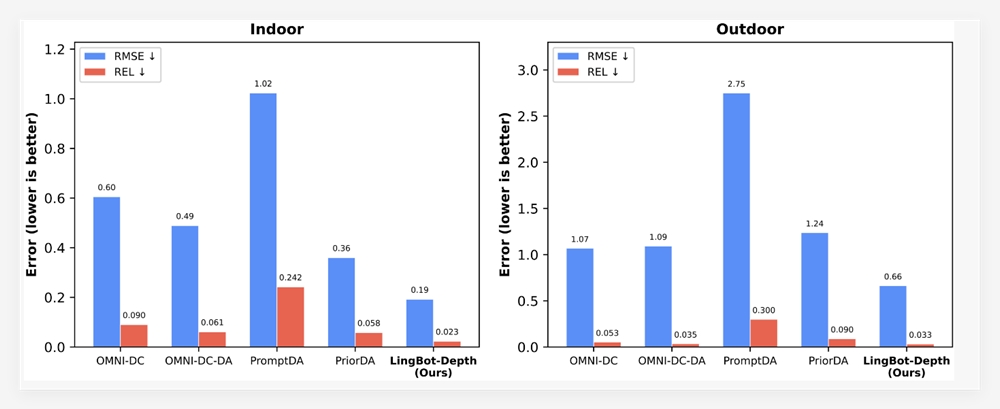
该创新解决了开源模型中长期存在的难题:传统模型通常擅长分析或创作中的单一功能,但难以兼顾两者。苹果的研究论文展示了Manzano处理复杂提示的能力,其表现可与GPT-4o和谷歌的"Nano Banana"(Gemini 2.5闪存图像生成)相媲美。

混合架构
Manzano采用混合图像分词器,可输出:
- 连续token:使用浮点数表示图像以实现理解功能
- 离散token:将图像划分为固定类别以实现生成功能
这种架构通过从同一编码器派生两种token类型,减少了传统模型中常见的冲突。
可扩展设计
该系统包含三个核心组件:
- 混合分词器
- 统一语言模型
- 独立图像解码器(提供90M、175M和352M参数版本)
最大配置支持高达2048像素的分辨率,测试显示当参数数量从3亿增加到30亿时性能持续提升。
性能基准测试
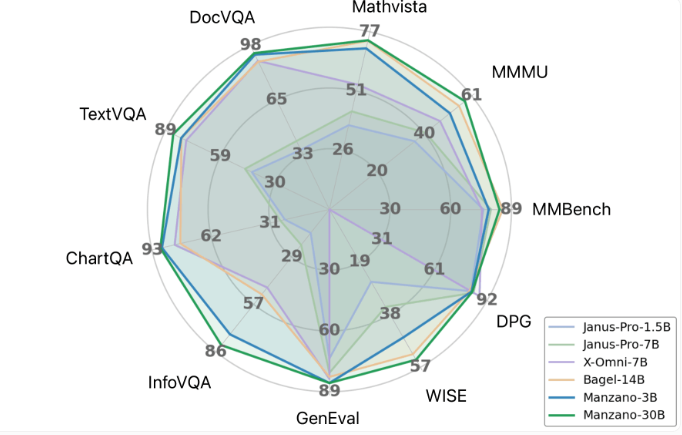
苹果报告了多项测试中的优异表现,特别是在:
- 图表分析
- 文档解读
- 文字密集图像任务 该模型还具备以下创意功能:
- 风格迁移
- 图像修复/扩展
- 深度估算
- 基于提示的编辑 模块化设计表明其具有超越当前能力的多模态AI应用潜力。 完整研究论文详见:https://arxiv.org/abs/2509.16197 --- ### 关键要点: 🌟 双重能力 - 同步实现图像理解与生成 🔍 商用级性能 - 媲美GPT-4o和Gemini系统 ⚙️ 混合分词器 - 减少分析/创作功能间的冲突 📈 可扩展架构 - 三种解码器尺寸支持最高2048px分辨率