腾讯OCR技术突破:小模型,大成效
腾讯OCR颠覆者:效率与卓越并存
逆袭AI领域"越大越好"的趋势,腾讯发布开源光学字符识别模型HunyuanOCR——这款计算资源需求极小的模型实现了惊人准确率。仅10亿参数的紧凑设计正在科技界引发轰动。

小体积,高性能
核心技术在于腾讯自研的混元架构。与传统需要多步处理的OCR系统不同,HunyuanOCR采用优雅的端到端方案:输入图像即可通过单次高效处理直接输出可用文本——无需组装步骤。
"我们本质上打造了文本识别的瑞士军刀",腾讯项目负责人解释道,"从褪色收据到艺术字体广告,它都能保持惊人的一致性"。
突破性基准测试
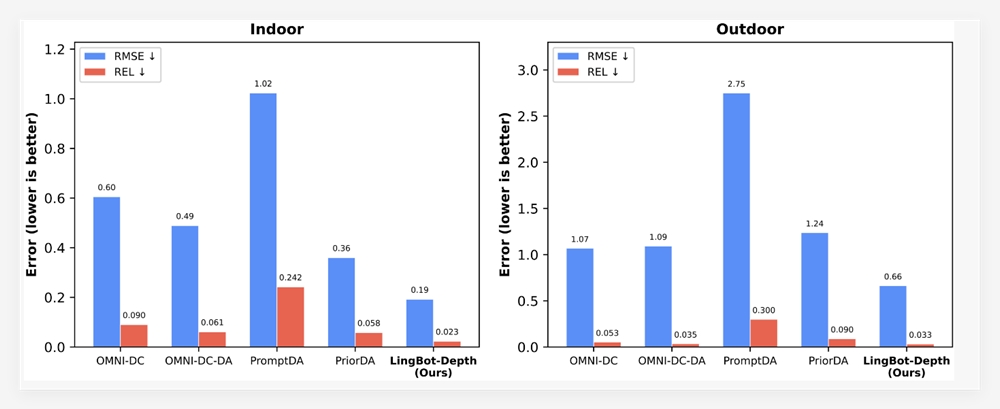
数据说明一切:
- 94.1分 复杂文档解析得分(超越谷歌Gemini3-pro)
- 860总分 OCR性能(在30亿参数以下模型中夺冠)
- 14种语言 内置翻译支持
最令人印象深刻的是:无论是解读医生手写体还是从褶皱发票提取数据,该模型在不同场景下均保持高准确率。
即装即用的技术
HunyuanOCR不仅赢在测试场,更解决实际问题:
- 自动化繁琐的文档数字化流程
- 为旅行者提供实时翻译应用支持
- 赋能视障人士辅助工具
该模型甚至理解文档结构,能将扫描页面重组为正确阅读顺序,并保留LaTeX公式和HTML表格等复杂格式。
开发者已可通过腾讯GitHub仓库体验这项技术。早期使用者反馈其轻量架构在普通硬件上运行流畅——这对移动应用可能是革命性的改变。
核心亮点:
- 💡 效率突破:10亿参数模型媲美更大体量方案
- 📑 文档掌控:处理复杂版式、公式及多语言内容
- 🌍 实用超能力:从收据扫描到实时拍照翻译