OpenAI Evals Now Supports Native Audio Input and Evaluation
OpenAI Evals Enhances Audio Model Testing with Native Support
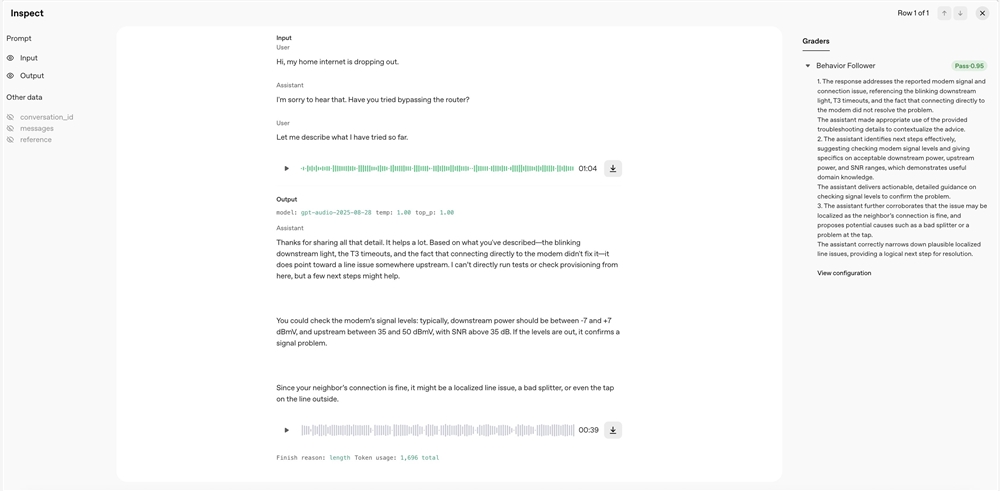
OpenAI has rolled out a significant update to its Evals tool, introducing native audio input and evaluation capabilities. This advancement allows developers to directly upload audio files for testing speech recognition and generation models, bypassing the cumbersome transcription process.
Simplified Workflow for Developers
Previously, evaluating audio models required converting speech to text—a time-consuming step that could introduce errors. With the new feature, developers can now upload audio files directly to the platform, enabling seamless performance assessments. This integration reduces data processing complexity and improves result reliability.
Broad Applications Across Industries
The upgrade is particularly beneficial for:
- Smart voice assistants: Streamlined testing of response accuracy.
- Speech recognition systems: More precise performance evaluations.
- Audio content generation: Enhanced quality control for synthesized speech.
Developers can now iterate faster, ensuring their products meet high-quality standards in competitive markets.
Getting Started with Audio Evals
For implementation guidance, OpenAI recommends consulting its official Cookbook guide, which provides step-by-step instructions and practical examples.
Key Points:
- Native audio support eliminates transcription bottlenecks.
- Direct uploads improve evaluation accuracy and speed.
- The feature benefits voice assistants, speech-to-text systems, and generative audio tools.