Microsoft Open-Sources VibeVoice TTS Model with Breakthrough Features
Microsoft Releases Open-Source VibeVoice TTS Model with Industry-Leading Capabilities
Microsoft has made waves in the artificial intelligence community with the open-source release of its VibeVoice text-to-speech (TTS) model. The announcement, made on August 26, 2025, introduces groundbreaking features that push the boundaries of speech synthesis technology.
Unprecedented Speech Duration
The most notable advancement is VibeVoice's ability to generate continuous speech up to 90 minutes without quality degradation. This capability addresses a critical limitation in existing TTS systems, which typically struggle with maintaining consistency in longer audio segments. The extended duration makes the model particularly valuable for:
- Audiobook production
- Educational content creation
- Podcast generation
- Long-form narration projects
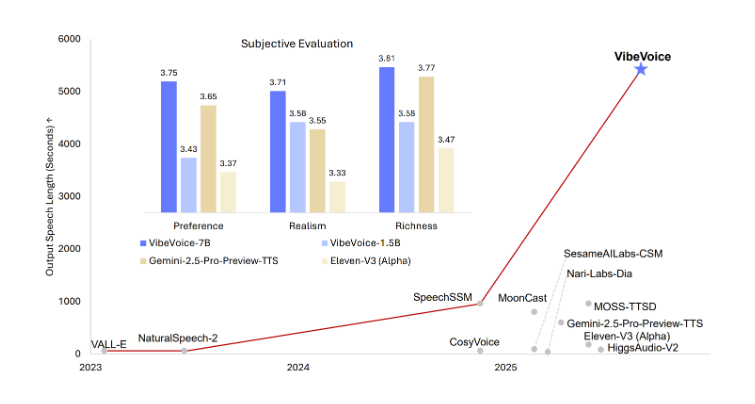
Multi-Speaker Dialogue Innovation
VibeVoice sets a new standard for conversational AI by supporting natural-sounding dialogues between up to four distinct voices. This represents a significant leap from conventional TTS systems that typically handle only one or two speakers. The model demonstrates exceptional performance in:
- Maintaining consistent voice characteristics across speakers
- Managing natural turn-taking in conversations
- Preserving emotional tone throughout extended exchanges
The technology shows particular promise for applications in virtual meeting simulations, interactive storytelling, and multi-character audio productions.
Superior Chinese Language Performance
The model delivers exceptional results in Mandarin Chinese, with precise tone reproduction and natural prosody. Microsoft's focus on Chinese language support reflects both the technical challenges of tonal languages and the growing importance of the Chinese market in AI applications.
Key advantages include:
- Accurate pronunciation of complex characters
- Natural rhythm and intonation patterns
- Contextual understanding for proper word stress
- Dialect-aware synthesis capabilities
Enhanced Audio Production Features
VibeVoice incorporates professional-grade audio production capabilities, including:
- Background music integration for creating immersive listening experiences
- Dynamic volume adjustment between speech and music tracks
- Seamless transitions between different audio elements These features enable content creators to produce polished audio outputs without requiring additional editing software.
Open-Source Accessibility
The model's release on GitHub and Hugging Face (https://huggingface.co/microsoft/VibeVoice-1.5B) represents Microsoft's commitment to democratizing advanced AI technologies. The open-source approach offers:
- Free access to state-of-the-art TTS technology
- Opportunities for community-driven improvements
- Lower barriers to entry for developers worldwide
- Customization potential for specific use cases
The release follows growing industry demand for more accessible and adaptable speech synthesis solutions.
Key Points:
- 90-minute continuous speech generation capability breaks previous duration barriers
- Four-person dialogue support enables complex conversational scenarios
- Exceptional Chinese language performance meets growing demand for localized solutions
- Professional audio features including background music integration
- Open-source availability encourages widespread adoption and innovation