Meituan's New AI Model Sees, Hears and Understands Like Humans
Meituan Breaks New Ground with Unified AI Perception
In a significant leap for artificial intelligence, Meituan has introduced LongCat-Next - a model that fundamentally changes how machines process different types of information. Forget about separate systems for text, images and audio; this innovation treats them all as equals from the ground up.
The Technology Behind the Breakthrough
At its core lies the DiNA (Discrete Native Autoregressive) architecture, which works like a universal translator for sensory data:
- One system to rule them all: Whether analyzing financial reports or interpreting family photos, LongCat-Next uses identical processing methods
- Understanding equals creating: The same mechanism that helps it read text also enables it to generate realistic images
- Space-age compression: Its visual processing can shrink images by 28 times without losing crucial details - perfect for tasks like document digitization
Real-World Performance That Turns Heads
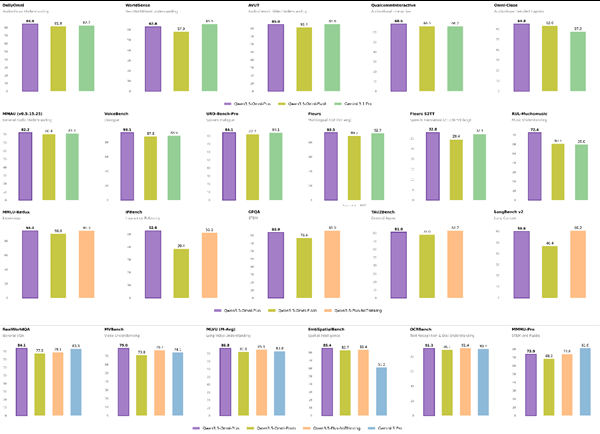
The model isn't just theoretically impressive - it's delivering results that challenge specialized single-purpose systems:
- Outperforms dedicated document analysis tools in reading dense financial statements
- Scores an impressive 83.1 on complex visual logic tests (MathVista)
- Maintains top-tier language skills while adding speech generation capabilities
"What excites us most," explains a Meituan engineer, "is seeing the model make connections between different types of information naturally - just like humans do when we look at a diagram while listening to an explanation."
Why This Matters for Tomorrow's Technology
This breakthrough suggests we're approaching a future where AI can:
- Truly understand multimedia content as a cohesive whole
- Develop more intuitive ways to interact with digital systems
- Bridge the gap between virtual intelligence and physical world applications
The company has open-sourced both the model and its compression technology, inviting developers worldwide to build upon this foundation.
Key Points:
- Native multimodal processing eliminates need for separate image/text/audio systems
- DiNA architecture provides unified framework for all data types
- Proven performance exceeds specialized models in multiple benchmarks
- Open-source release accelerates development of physical-world AI applications