Meituan's LongCat-Next: A New AI That Sees, Hears and Understands Like Humans
Meituan Breaks New Ground with Unified AI Model
In a move that could redefine how artificial intelligence interacts with our world, Meituan has introduced LongCat-Next - a model that processes visual and auditory information as naturally as it handles text. This isn't just another incremental improvement; it's a fundamental shift in how AI understands multiple types of data simultaneously.
How It Works: Seeing the World Through AI's Eyes
At its core lies the DiNA (Discrete Native Autoregressive) architecture, which eliminates the artificial barriers between different data types:
- One System to Rule Them All: Text, images and audio all flow through the same processing pipeline using identical parameters and mechanisms
- Understanding Meets Creation: The same mathematical framework handles both comprehension (when reading text) and generation (when creating images)
- Smart Compression: The dNaViT Visual Tokenizer can shrink high-resolution images by 28 times without losing crucial details - perfect for analyzing complex documents or financial reports
"What makes this special," explains a Meituan engineer familiar with the project, "is that we're not just bolting on vision capabilities to a language model. From its foundation, LongCat-Next thinks about all information the same way."
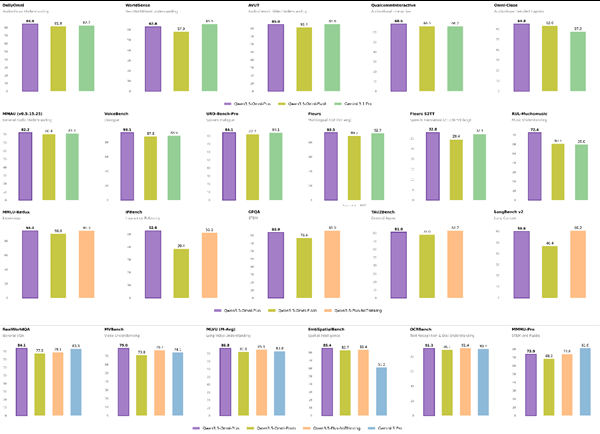
Real-World Performance That Surprises Experts
The model has already turned heads with its capabilities:
- Outperformed specialized document analysis tools on dense text interpretation
- Scored an impressive 83.1 on visual math problems (MathVista), showing logical reasoning skills rare in multimodal systems
- Maintains top-tier language understanding while handling speech generation with customizable voices
Perhaps most surprisingly, these results challenge the long-held belief that converting continuous data (like images) into discrete tokens inevitably degrades quality. LongCat-Next proves information can be preserved - even enhanced - through this approach.
Why This Matters for AI's Future
The implications extend far beyond technical benchmarks. For years, AI systems have treated language as their primary mode of thought while struggling to truly integrate other senses. LongCat-Next suggests a future where:
- Robots might navigate spaces as naturally as they process instructions
- Medical AI could correlate scans with patient histories more intuitively
- Creative tools might blend visual and verbal concepts seamlessly
Meituan has open-sourced both the model and its tokenizer, inviting developers to explore this new approach. As one researcher put it: "We're not just building better AI tools - we're creating systems that experience information more like we do."
Key Points:
- Unified Processing: First model to natively handle text, images and speech through identical mechanisms
- Proven Performance: Outperforms specialized models in document analysis and visual reasoning
- Open Access: Both model and tokenizer available for developers to build upon
- Future Potential: Could enable more natural human-AI interaction across multiple industries