DeepSeek V4 Launches with Two Flavors: Fast and Powerful AI at New Price Points
DeepSeek V4 Arrives with Dual Options
China's AI landscape just got more interesting with DeepSeek's launch of its V4 model series. The company is taking a smart approach by offering two distinct versions - think of it like choosing between a sports car and a luxury sedan, each built for different driving conditions.
Meet the Models
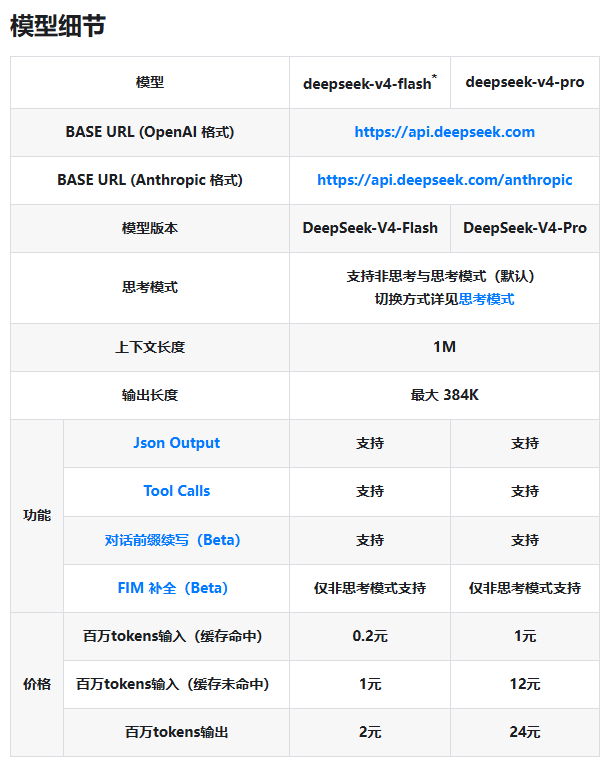
The DeepSeek-V4-Flash version is your go-to for everyday AI tasks that need quick responses without breaking the bank. Need fast chat responses or basic text processing? This is your economical choice.
For heavier lifting, the DeepSeek-V4-Pro steps up to handle complex logic problems and demanding computing jobs. It's the equivalent of upgrading from economy to business class when you need that extra brainpower.
Both models boast impressive specs:
- Support for context windows up to 1 million tokens
- Maximum output length of 384K tokens
- JSON output and Tool Calls capabilities
- Thinking mode (with some exceptions)
Pay-as-You-Go AI Pricing
The pricing structure reveals DeepSeek's clever strategy to encourage efficient computing:
| Model | Input (Cache Hit) | Input (Cache Miss) | Output |
|---|
The dramatic price difference between cached and uncached inputs isn't accidental - it's designed to reward developers who optimize their systems. Think of it like getting a discount for bringing your own shopping bags.
Why This Pricing Matters
The Flash version at just ¥1 per million tokens (without caching) makes powerful AI accessible to more developers. Meanwhile, the Pro version offers enterprises an affordable domestic alternative for building sophisticated systems like knowledge bases or automated agents.
"This pricing structure encourages smarter system design," explains an industry analyst. "By rewarding efficient caching, DeepSeek helps businesses control costs while still delivering top-tier performance."
Transition Tips for Developers
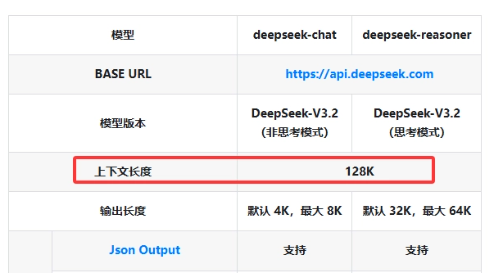
The company warns that older model names (deepseek-chat and deepseek-reasoner) will eventually be retired. Developers should start migrating to:
deepseek-v4-flashfor standard tasksdeepseek-v4-profor thinking-mode applications
The full API documentation provides migration guidance to make this switch painless.
Key Points:
- Two-model strategy covers both lightweight and heavy-duty AI needs
- Innovative pricing rewards efficient caching practices
- Flash version offers budget-friendly access at ¥1/million tokens
- Pro version delivers advanced capabilities for complex applications
- Transition period underway for existing implementations