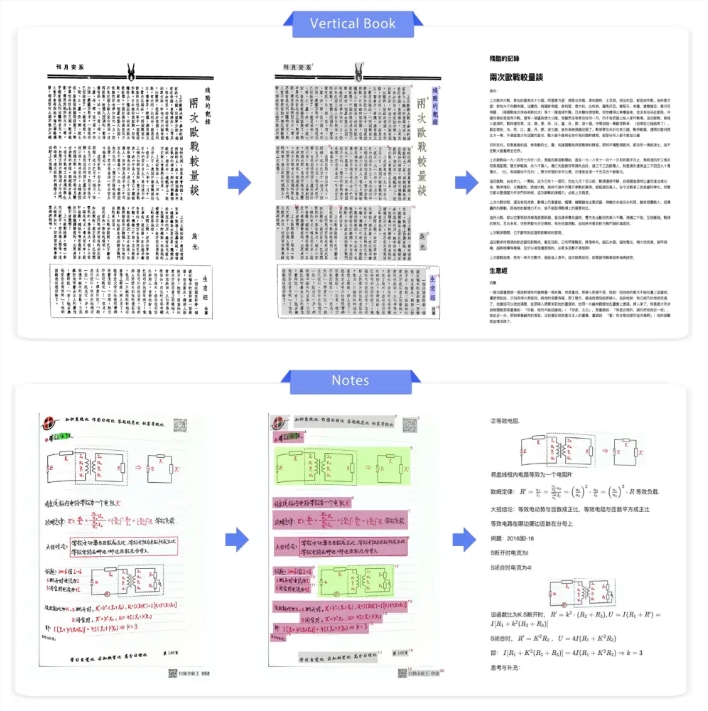
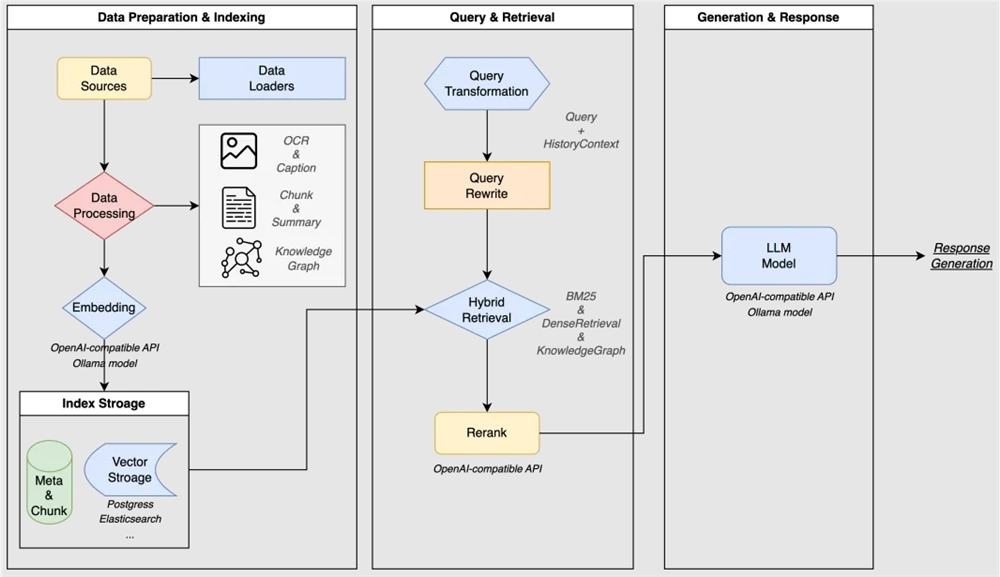
DeepSeek-OCR Introduces Visual Memory Compression for AI
DeepSeek-OCR Revolutionizes Long Text Processing with Visual Compression
DeepSeek has launched DeepSeek-OCR, a groundbreaking document understanding model that introduces a novel "Visual Memory Compression" mechanism. This innovation addresses the growing challenge of computational resource consumption when large language models (LLMs) process extensive texts.

How Visual Memory Compression Works
The system operates through three key steps:
- Text-to-image conversion: Long text passages are compressed into single images
- Visual tokenization: A visual model further compresses these images into minimal "visual tokens"
- Decoding: The language model reconstructs the original text from these visual tokens
This approach enables AI to "read by looking at pictures" rather than processing text word-by-word, dramatically improving efficiency.
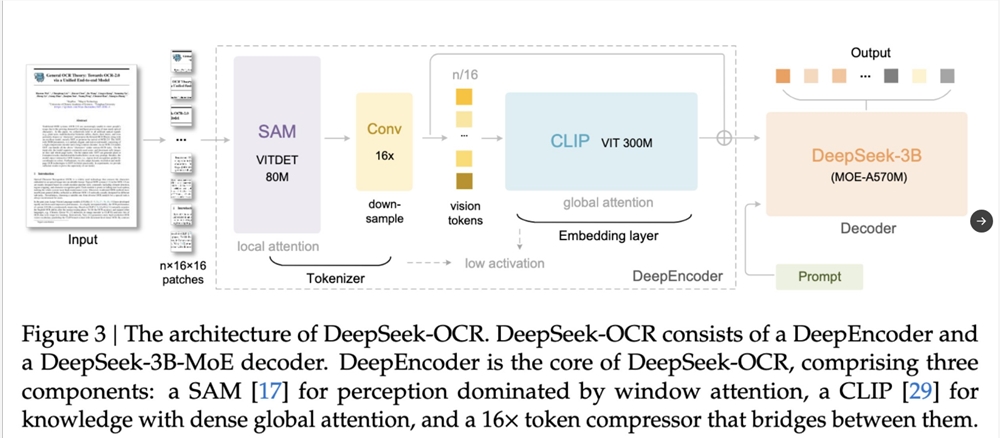
Performance Breakthroughs
Initial demonstrations show remarkable results:
- 10x compression: 1000 words reduced to just 100 visual tokens
- 97% accuracy: Near-perfect text reconstruction during decompression
- Reduced computational load: Significantly lowers memory requirements for LLMs
The technology shows particular promise in overcoming current limitations in:
- Processing multi-page documents and books
- Long-term memory storage for AI systems
- Efficient information archiving solutions
Human-Like Memory Processing
The system draws inspiration from human cognition:
| Feature | Implementation |
|---|
This mimics the natural human "forgetting curve," where recent information remains sharp while older memories fade.
Key Points:
- DeepSeek-OCR introduces revolutionary visual compression for text processing
The system achieves:
- 10x compression rates
- 97% reconstruction accuracy Potential applications include:
- Overcoming LLM memory limitations
- Enabling efficient long-context processing
- Creating sustainable AI memory architectures