Claude Opus 4.6 Takes the AI Crown, But Can It Hold On?
Claude Opus 4.6 Outshines GPT-5.2 in Latest AI Benchmark Tests
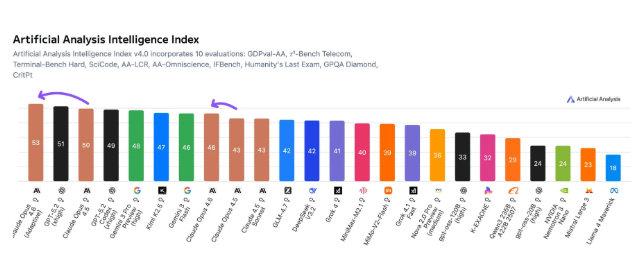
The artificial intelligence landscape just got more interesting. Anthropic's Claude Opus 4.6 has claimed the top spot in the prestigious Artificial Analysis Intelligence Index, delivering standout performance across multiple challenging tests.
A Clear Winner Emerges
In comprehensive testing that evaluated ten different capabilities - from programming to scientific reasoning - Opus 4.6 particularly excelled in three areas:
- Agent task work (managing complex multi-step processes)
- Terminal programming (writing and debugging code)
- Physics research (solving complex scientific problems)
The results reveal an intriguing efficiency advantage: while Opus 4.6 processed about 58 million output tokens during testing (double its predecessor's count), it still came out far ahead of GPT-5.2's whopping 130 million token consumption.
The Cost of Excellence
Performance comes at a price - literally:
- Opus 4.6 operation cost: $2,486 per test run
- GPT-5.2 operation cost: $2,304 per test run
That extra $182 buys significantly better efficiency, but whether that translates to real-world value depends on specific use cases.
The model is currently available through Claude.ai and major cloud platforms including Google Vertex and AWS Bedrock, making it accessible to developers and businesses alike.
The Competition Isn't Standing Still
OpenAI isn't taking this lying down:
- Their new programming tool Codex 5.3 is already undergoing testing
- Early indications suggest it could dominate in coding-related tasks
- Industry analysts predict it may reclaim the top spot once full benchmark results are in
The race for AI supremacy continues to accelerate, with each breakthrough quickly matched or surpassed by competitors.
What This Means for Users
For businesses and developers:
- Right now, Opus 4.6 offers superior performance for complex tasks
- Long-term, expect rapid iterations from all major players
- The choice between models increasingly depends on specific needs rather than raw rankings
The only certainty? This technological arms race shows no signs of slowing down.
Key Points:
- 🏆 Claude Opus 4.6 leads current AI benchmarks
- ⚡ Processes data more efficiently than GPT-5.2
- 💰 Comes at a slightly higher operational cost
- ⏳ OpenAI's Codex 5.3 may soon challenge for top spot


