Claude Code Gets a Speed Boost: Local AI Development Just Got Faster
Claude Code's Performance Leap
In a significant advancement for local AI development, tests conducted by JeecgBoot developers reveal that Claude Code can now run substantially faster when paired with a community-modified version of Gemma 4. Under Mac Studio M4Max environments, the modified setup achieved generation speeds of up to 78 tokens per second - a five to sixfold improvement over standard implementations.
Why Model Choice Matters More Than Optimization
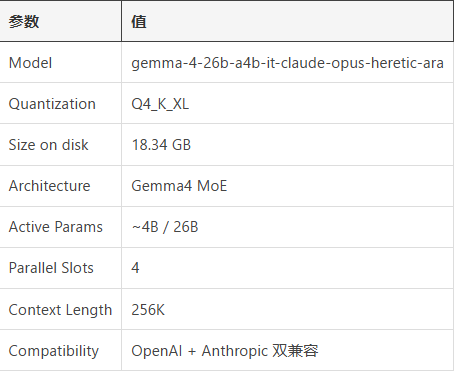
The secret sauce? Developers bypassed the official model in favor of a community-tweaked version called gemma-4-26b-a4b-it-claude-opus-heretic-ara. This alternative delivers impressive capabilities:
- Blazing speed: Output reaching 78 tokens per second eclipses the original's performance
- Efficient architecture: Using a A4B MoE design that activates just 4 billion of its 26 billion parameters per inference
- Extended memory: Supporting 256K context windows while maintaining compatibility with Anthropic's API format
The Speed Tradeoff
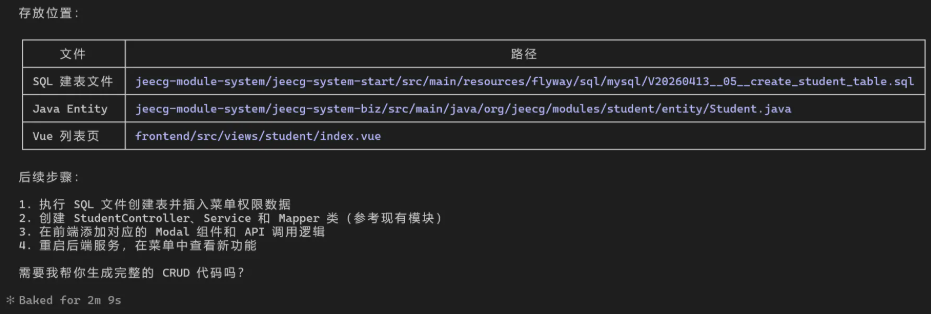
While the raw generation speed impresses, developers discovered an interesting wrinkle in practical applications. Even with faster processing, completing specific tasks - like generating teacher table code - still required about 90 seconds. The bottleneck? Claude Code's multi-step decision process.
"The system thinks before it acts, which is great for code quality but adds latency," explains one developer. For simpler queries, they recommend tools like LM Studio instead.
Practical Applications Shine
When tested on JeecgBoot framework projects, the Claude Code/Gemma combo demonstrated real-world value:
- Generated standardized SQL that automatically met Flyway requirements
- Produced modern Vue3/TypeScript frontend code
- Created complete backend skeletons (controllers, services, mappers)
Though complex methods still needed human refinement, the tool significantly reduced boilerplate coding.
Smart Deployment Strategy
The testing team suggests a balanced approach:
- Local models (80% of work): Ideal for routine CRUD operations and sensitive internal projects
- Cloud APIs (20% of work): Better suited for complex architecture and security-critical components
Key Points
- Local AI development achieves new speed benchmarks with modified models
- Claude Code/Gemma integration shows 5-6x performance gains
- Practical implementations reveal tradeoffs between speed and agentic processes
- Hybrid deployment strategy balances privacy, cost and quality
- Modern hardware makes high-performance local AI increasingly accessible