Alibaba Unveils Qwen3-Omni: A Multimodal AI Breakthrough
Alibaba's Qwen3-Omni Redefines Multimodal AI Capabilities
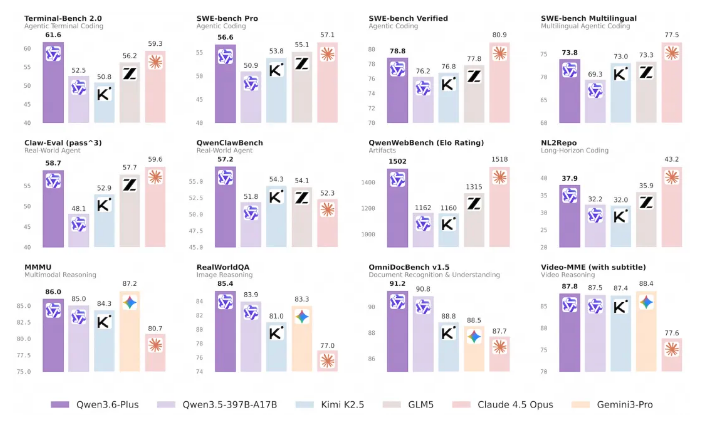
Alibaba Group has made a significant leap in artificial intelligence with the release of Qwen3-Omni, its latest multimodal pre-training large model series. This groundbreaking technology demonstrates unprecedented ability to process and understand multiple data types - including audio, video, and text - with human-like comprehension.
Benchmark-Dominating Performance
The new model has achieved State Of The Art (SOTA) levels in 22 out of 36 audio and video benchmark tests, establishing itself as a leader among open-source models in 32 evaluations. Particularly impressive is its performance in:
- Speech recognition
- Audio understanding
- Cross-modal processing
 Image source note: The image was generated by AI
Image source note: The image was generated by AI
Revolutionary Training Methodology
Qwen3-Omni's development team took an innovative approach by modeling the AI's training after human cognitive development. The system underwent simultaneous multimodal training in:
- Listening (audio processing)
- Speaking (audio generation)
- Writing (text comprehension)
This methodology combines unimodal and cross-modal data, allowing the model to maintain exceptional performance across all modalities without sacrificing specialization.
Competitive Edge Over Tech Giants
The model demonstrates capabilities comparable to Google's Gemini 2.5-Pro in speech-related tasks while offering broader multimodal functionality. Industry analysts note this positions Alibaba as:
- A serious competitor in global AI development
- An innovator in integrated multimodal systems
- A potential leader in practical AI applications
Future Applications and Impact
The release opens doors for transformative applications across multiple sectors:
- Intelligent customer service with natural voice interactions
- Automated content creation combining visual and textual elements
- Advanced voice assistants with contextual understanding
- Educational tools leveraging multiple learning modalities
The technology promises more natural human-machine interactions while reducing the need for specialized single-mode systems.
Key Points:
- Qwen3-Omni processes audio, video, and text simultaneously
- Outperforms competitors in 32 benchmark tests
- Training mimics human cognitive development
- Matches Google's Gemini 2.5-Pro speech capabilities
- Enables more natural human-AI interactions