Alibaba's Tiny AI Model Packs a Punch with Smart Upcycling Technique
Alibaba's AI Breakthrough: Doing More with Less
In an impressive display of engineering ingenuity, Alibaba's International Digital Commerce team has unveiled Marco-Mini-Instruct - a new member of their Marco-MoE series that challenges conventional thinking about AI model scaling. What makes this release special isn't its size, but how it achieves big results from small beginnings.

Efficiency That Surprises
The numbers tell an intriguing story: while the model boasts 17.3 billion total parameters, it cleverly activates only 860 million (about 5%) during operation. This selective activation translates to remarkable efficiency - the kind that lets the model run smoothly on everyday computer processors without specialized hardware. Early tests show it processing about 30 tokens per second on a setup with 8-bit quantization and four DDR4 2400 memory modules.
The Magic of Upcycling
Here's where it gets really interesting. Instead of building from scratch, researchers took the existing Qwen3-0.6B-Base model and gave it an extraordinary upgrade. Using what they call 'upcycling' technology, they transformed this modest model into something far more capable.
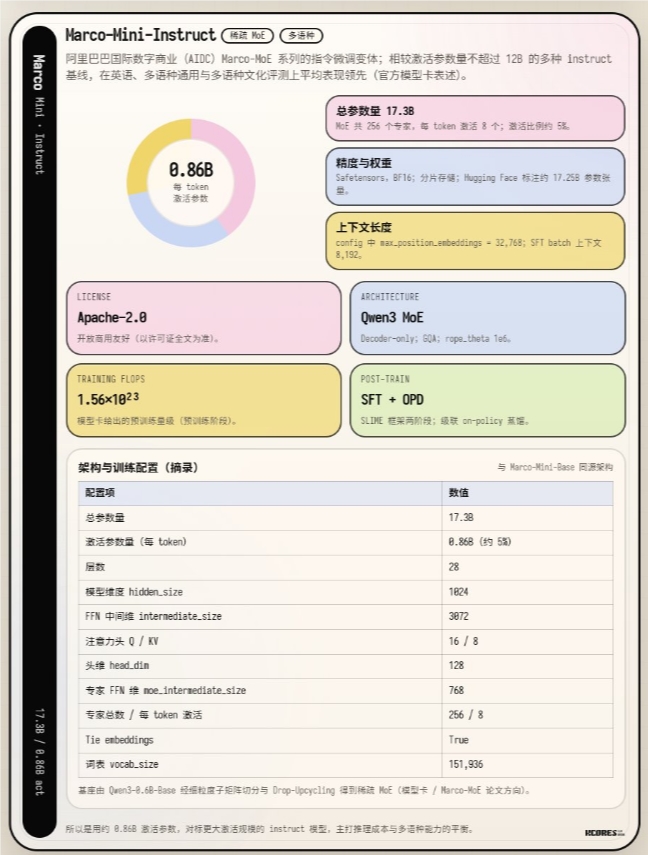
The process involves some clever tricks:
- Smart division: Parts of the original model were split or copied to create multiple specialized 'experts'
- Intelligent routing: A mechanism decides which experts to consult for different tasks
- Strategic dropping: During training, some experts or paths were randomly ignored to improve robustness
This combination of techniques provides a smoother path from traditional 'dense' models to the more efficient MoE (Mixture of Experts) architecture.
Training with Wisdom
The team didn't stop at structural innovations. For the model's 'education', they employed a cascaded distillation approach:
- Initial refinement using the capable Qwen3-30B-A3B-Instruct model as teacher
- Advanced training under the even more sophisticated Qwen3-Next-80B-A3B-Instruct
The curriculum covered everything from following instructions to complex reasoning and mathematical ability, creating a well-rounded AI assistant that punches above its weight.
Performance That Impresses
Benchmark results validate the approach. Despite activating fewer parameters than many competitors, Marco-Mini-Instruct frequently outperforms dense models several times its size, including the Qwen3-4B. It's proof that in AI, smarter design can beat brute force scaling.
Why This Matters
This development opens new possibilities for AI accessibility. The relatively modest hardware requirements (64 GPUs for 24-110 hours during different training phases) mean smaller teams can experiment with MoE architectures without enormous computational budgets.
Alibaba's achievement underscores an important lesson in AI development: breakthrough performance doesn't always come from stacking more parameters. Sometimes, it's about working smarter with what you have - a principle that could shape the next generation of efficient, practical AI systems.
Key Points:
- Resource-smart AI: 17.3B parameter model activates just 5% during use
- Hardware-friendly: Runs efficiently on standard CPUs at ~30 tokens/sec
- Creative origins: Transformed from smaller model via 'upcycling' technique
- Training innovation: Uses cascaded distillation for balanced capability
- Accessible future: Lowers barriers for MoE model development and deployment