Alibaba's AI Team Unveils Ovis2.5: Breakthrough in Visual Reasoning
Alibaba Advances Multimodal AI with Ovis2.5 Release
The AI Team (AIDC-AI) of Alibaba International Digital Trade Group has introduced Ovis2.5, a cutting-edge multimodal language model available in two configurations: 9B and 2B parameters. This release marks a significant leap in economic visual reasoning solutions, combining compact size with industry-leading performance.
Key Innovations in Ovis2.5
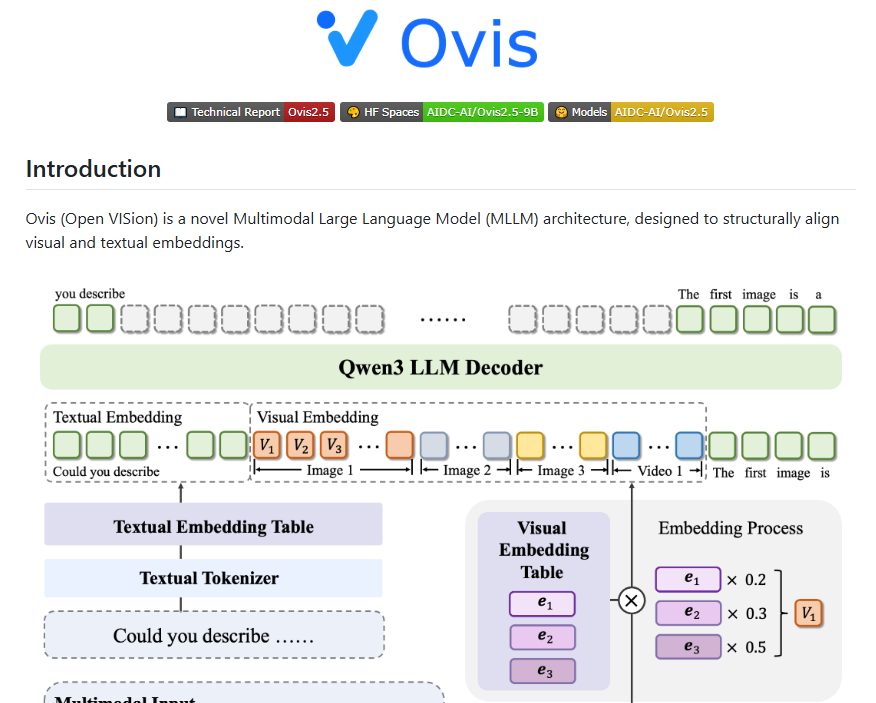
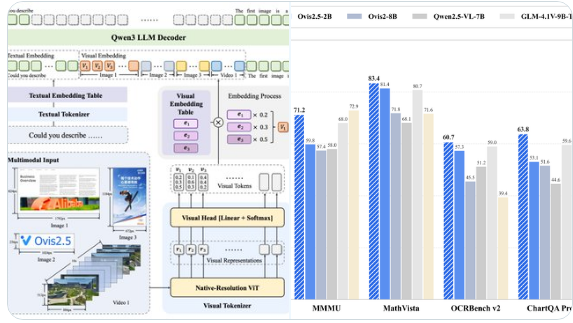
Native Resolution Recognition: Utilizing the NaViT Visual Encoder, Ovis2.5 preserves fine image details without quality loss, enabling superior visual processing capabilities.
Advanced Reasoning Capabilities: The model features a "thinking mode" potentially leveraging Alibaba's Qwen3 technology. Beyond standard chain-of-thought (CoT) reasoning, it supports self-correction and configurable thinking budgets for improved accuracy.
Industry-Leading Document Analysis: Ovis2.5 outperforms competitors in complex diagram interpretation, document understanding (including tables/forms), and optical character recognition (OCR) at both parameter sizes.
Broad Task Competency: Demonstrates strong performance across image reasoning, video understanding, and visual localization benchmarks, showcasing versatile multimodal abilities.
Strategic Impact
The open-source availability on GitHub and Hugging Face positions Ovis2.5 as an accessible solution for developers needing combined visual-textual analysis. Alibaba emphasizes this release as part of their ongoing innovation in multimodal AI technology.
Key Points:
- Two model sizes (9B/2B parameters) balance performance with efficiency
- Native resolution handling via NaViT encoder technology
- Self-correcting reasoning capabilities with configurable thinking budgets
- Open-source availability accelerates industry adoption