腾讯混元2.0 AI模型实现重大飞跃
腾讯旗舰AI模型迎来重大升级
腾讯正式发布自主研发的大语言模型混元2.0,该新一代模型在多项能力上实现显著提升。这家科技巨头同时宣布将DeepSeek V3.2深度整合至其生态系统,两款模型现已登陆腾讯AI原生应用包括元宝和ima。
技术架构革新
升级后的模型采用先进的专家混合(MoE)架构,总参数量高达4060亿(其中320亿参数处于激活状态)。更令人印象深刻的是,它现在支持长达256K tokens的上下文窗口——使其能在对话或分析过程中处理并记忆更多信息。

相较于前代产品(Hunyuan-T1-20250822),2.0版本得益于增强的预训练数据和优化的强化学习策略,在以下复杂场景中表现更优:
- 数学与科学推理
- 编程任务
- 遵循详细指令
- 维持长对话上下文
专项能力突破
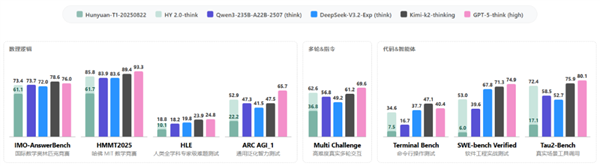
该模型在技术领域表现尤为突出。通过高质量训练数据和名为大型推演强化学习的技术,混元2.0已在多项权威基准测试中展现卓越性能,包括:
- 国际数学奥林匹克(IMO-AnswerBench)
- 哈佛-麻省理工数学竞赛(HMMT2025)
- 人类终极考试(HLE)
改进不仅限于原始计算能力。腾讯工程师通过重要性采样校正等方法,使模型在一致性和可靠性方面有所提升,这有助于训练过程更贴合实际使用场景。
应用场景扩展
对开发者和企业而言,最令人振奋的或许是模型在以下方面的增强能力:
- 复杂编程环境(Agentic Coding)
- 精密工具集成
- 多步骤问题求解(SWE-bench Verified, Tau2-Bench)
腾讯云已开放相关API和平台服务访问权限,允许第三方基于这些能力进行开发。
关键要点:
- 架构升级:采用MoE设计,总参数量4060亿(激活参数320亿)
- 记忆增强:支持256K上下文窗口,适用于长对话/复杂任务
- 性能飞跃:在数学/科学推理和编程方面表现突出
- 生态整合:现已登陆腾讯系应用,并向开发者开放API