印度Alpie AI模型引发热议——但它真的源自本土吗?
印度AI黑马震撼科技界
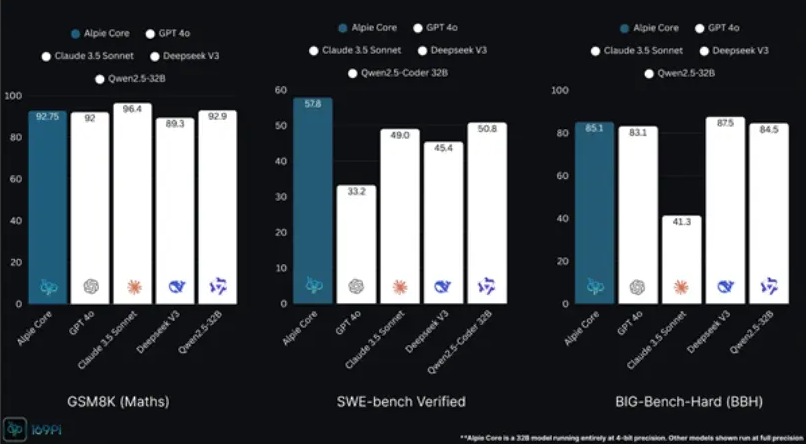
ChatGPT请让位——人工智能领域正迎来新的搅局者。印度公司169PI推出的Alpie模型以惊人表现攀升国际排名。在数学推理(GSM8K)和软件工程(SWE)基准测试中,这个仅320亿参数的"小模型"竟能与行业巨头分庭抗礼。
令人侧目的性能表现
Alpie的测试成绩讲述着非凡故事:在GSM8K数学基准上不仅超越中国DeepSeek V3,更追平OpenAI旗舰产品GPT-4o;SWE评估的编码任务中甚至优于Anthropic的Claude3.5——对于看似轻量级的模型实属不易。
"若通过原创研究达成这些结果将非常了不起,"AI研究员Priya Kumar博士指出,"但深究技术细节会发现情况更为复杂。"
开源技术的秘密配方
技术分析揭示Alpie并非完全的印度创新。该模型基于中国开源基础架构DeepSeek-R1-Distill-Qwen-32B构建,印度团队通过量化技术(将数值精度从16位降至4位)开发出可在16-24GB内存消费级GPU高效运行的版本。
这种优化带来切实优势:
- 显存需求降低75%(相比标准实现)
- 推理成本缩减至GPT-4o的约10%
- 让没有昂贵硬件的小型开发者获得可及性
"称其仅为'外壳'有失公允,"169PI首席技术官Rajiv Mehta辩称,"我们使现有技术具备了规模化实用价值。"
AI发展的宏观图景
Alpie现象折射全球AI三大趋势:
- 开源基础架构的战略价值
- 优化本身就是创新
- AI生态系统的区域专业化
尽管有人批评这是衍生作品,也有人视为对资源的巧妙适配。科技分析师Neha Patel认为:"不是每个国家都需要重复造轮子,印度发挥其在优化部署领域的优势合乎逻辑。"
核心要点:
- 基准测试亮点:虽体型小巧但Alpie在数学/编码任务媲美顶级模型
- 技术渊源:通过对中国开源模型DeepSeek量化改造而来
- 实用优势:以常规成本零头在消费级硬件高效运行
- 发展争议:引发全球AI竞赛中创新与优化的思考




