腾讯在叙事音频生成领域的AI突破
腾讯AI突破:从文本生成电影级音效
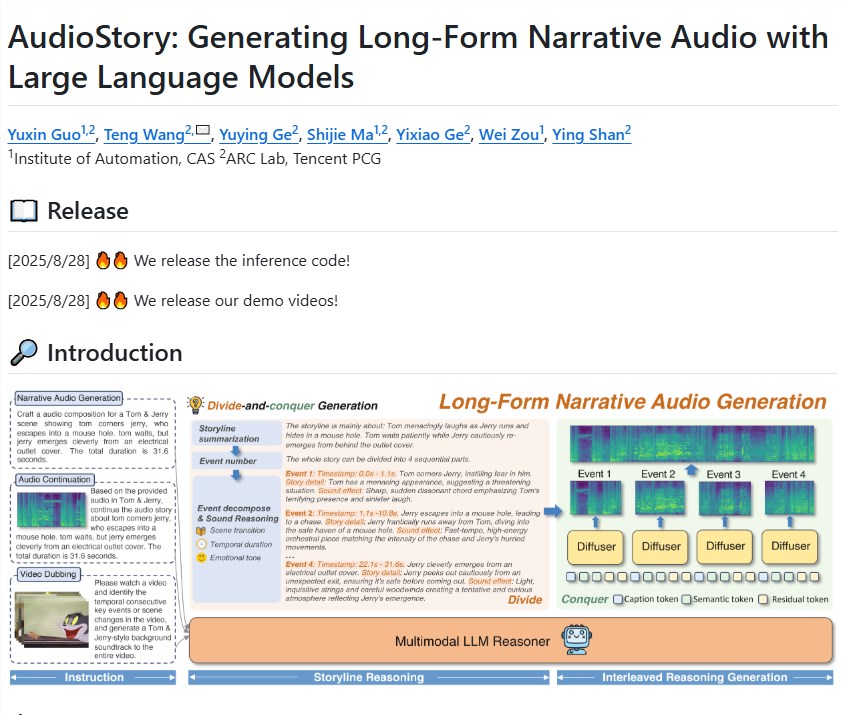
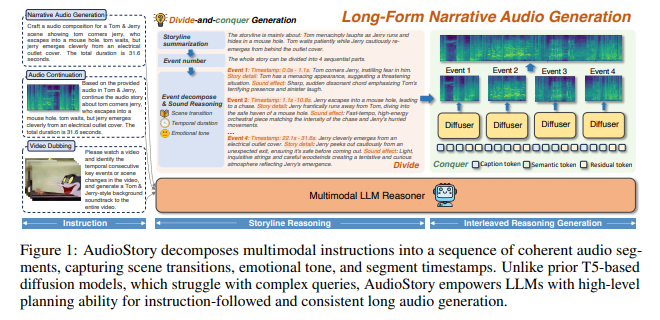
腾讯ARC实验室发布了AudioStory——一个革命性的AI系统,能够根据简单文字描述生成复杂的叙事音频序列。这项技术超越了基础音效生成的范畴,使机器能够制作出具有情感深度和时间精度的好莱坞级音频叙事作品。
AudioStory工作原理
系统采用精妙的"分而治之"策略:处理故事描述时,首先将叙事分解为带有精确时间戳和情感背景的有序音频事件。例如输入"神秘追逐场景"会被解析为:
- 水中飞溅的脚步声(营造紧张氛围)
- 雷鸣轰响(增强戏剧张力)
- 汽车急刹(高潮时刻)
- 门砰然关闭(场景收束)
技术创新
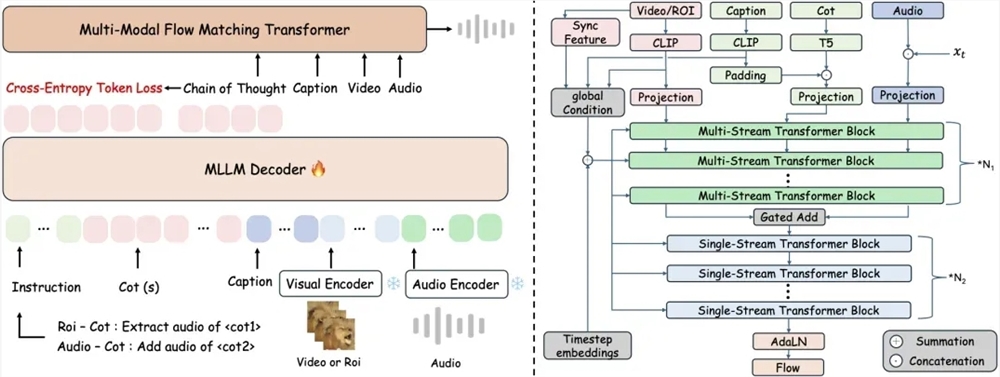
AudioStory的核心突破在于其分离式连接机制,解决了语义理解与音频生成间的传统割裂问题:
- 语义标记处理宏观故事含义
- 残差标记捕捉细微声音纹理与过渡
- 三阶段训练过程确保微观与宏观层面的质量
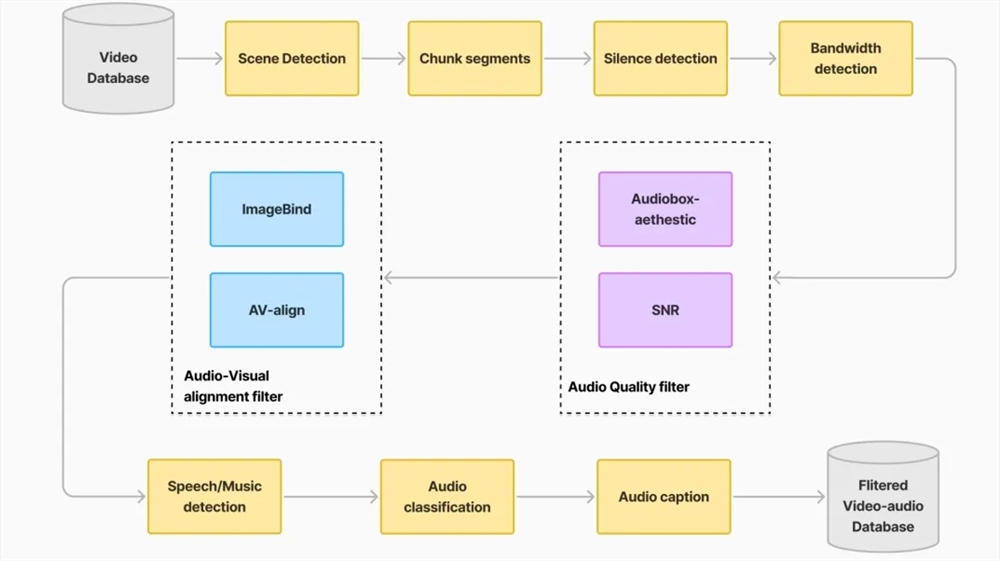
系统基于包含10,000个专业标注叙事音频样本的AudioStory-10K基准数据集进行训练,涵盖多种类型。
性能指标
对比测试显示AudioStory在以下方面超越竞争对手:
- 指令遵循准确率提升17.85%
- 更优的音频质量与时长匹配度
- 长篇幅叙事中表现异常稳定
实际应用
该技术可实现:
- 自动化电影配乐:根据无声视频生成同步背景音轨
- 动态音频延续:通过初始样本预测并创建后续音效
- 沉浸式游戏:实时生成响应式自适应声景
- AI有声书制作:生成带有环境语境的富有表现力的叙述
行业影响
这项突破标志着从基础声音模仿向真正音频叙事能力的转变。通过弥合技术性音频生成与艺术性叙事构建之间的鸿沟,腾讯将AI定位为创意合作伙伴而非单纯工具。
研究论文指出:"AudioStory展示了机器如何培养资深配音导演的艺术素养,为创意领域的人机协作开辟新可能。"
该技术特别适用于以下需求场景:
- 音频内容的快速原型设计
- 个性化媒体体验
通过丰富音频描述提升无障碍体验
关键要点
- 腾讯AudioStory可从文本生成电影级叙事音频
- 采用创新的分离式连接机制实现精准控制
- 指令准确率领先竞争对手近18%
- 为影视、游戏和无障碍领域开启新应用场景
- 代表AI向创意协作者而非工具的角色转变