腾讯开源AI视频音效模型HunyuanVideo-Foley
腾讯在AI生成视频音效领域取得突破
2025年8月28日,腾讯混元通过开源其HunyuanVideo-Foley模型,在多媒体AI领域取得重大进展——这是一个从视频输入生成同步音效的端到端解决方案。这一发展标志着克服当前AI生成内容"无声视频"限制的关键时刻。
技术创新与能力
该模型针对长期存在的音频生成挑战提出了三项突破性解决方案:
增强泛化能力:通过构建庞大的TV2A(文本-视频-音频)数据集,系统能够适应包括人类动作、野生动物、自然环境和动画场景在内的多样化内容。
双流架构:专有的多模态扩散变换器(MMDiT)框架平衡了视觉和文本语义,以产生复杂、分层的声景,同时保持与屏幕动作的完美同步。
音频保真度:采用表示对齐(REPA)损失函数确保专业级音频质量和时间一致性。
性能基准测试
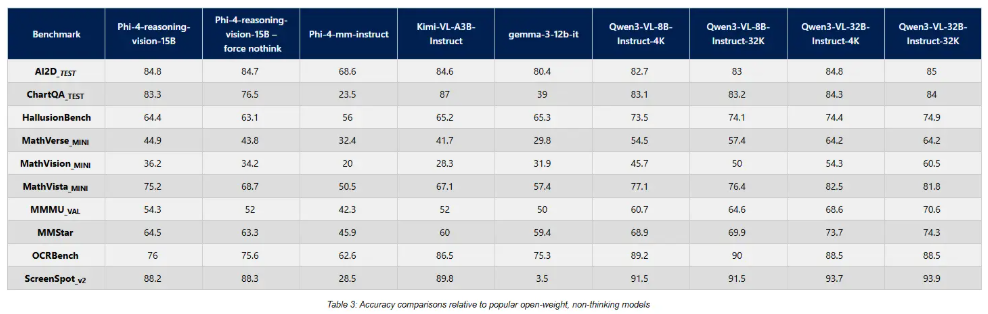
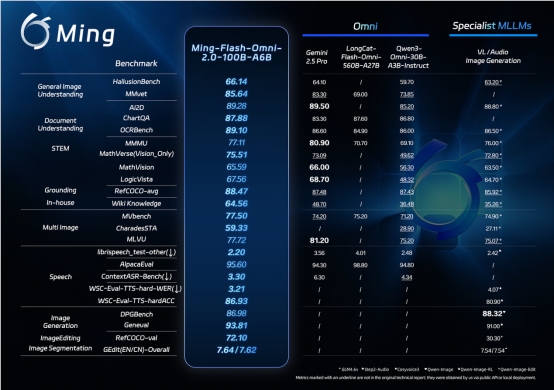
独立评估显示HunyuanVideo-Foley具有行业领先能力:
- 音频质量(PQ):从6.17提升至6.59
- 视觉对齐(IB):从0.27增加至0.35
- 时间同步(DeSync):从0.80优化至0.74
在三个维度(音频质量、语义匹配和时序)的主观测试中,该模型平均得分超过4.1/5分——接近专业制作标准。
实际应用
此次开源发布可实现:
- 内容创作者:为短视频即时生成上下文音效
- 电影制作:快速进行环境声音设计原型制作
- 游戏开发:高效创建沉浸式音频环境
获取方式
该模型现可通过多个平台访问:
关键点:
- 首个用于视频音效生成的端到端开源解决方案
- 在所有基准测试类别中均优于先前方法
- 为各类媒体应用普及专业级音频制作
- 立即可用于商业和研究用途