阿里通义开源ThinkSound,突破性音频生成模型问世
阿里巴巴ThinkSound革新AI音频生成技术
阿里巴巴语音AI团队通过开源ThinkSound实现了人工智能领域的重大突破,这是全球首个支持思维链推理的音频生成模型。这项革命性技术彻底改变了AI系统从视觉输入生成同步音频的方式。
从基础配音到结构化理解
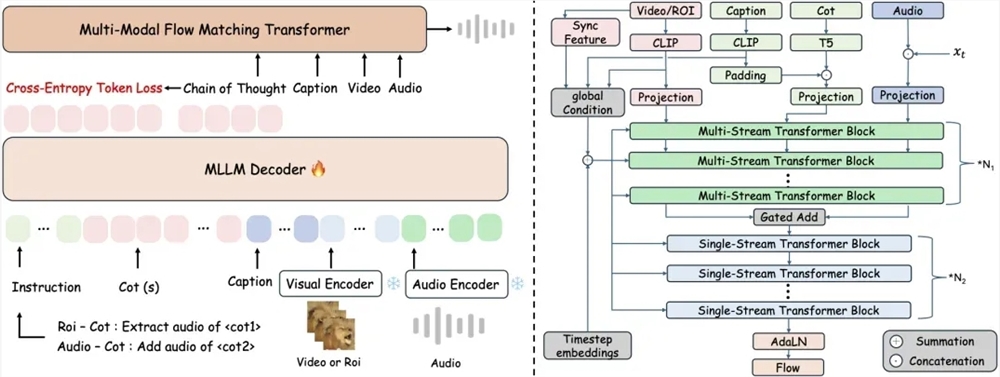
传统视频转音频系统往往难以维持视觉事件与对应声音间的时空关联性。ThinkSound通过创新的三阶段推理流程解决这一局限:
- 场景分析:系统首先解析整体运动与场景语义
- 声源聚焦:随后识别特定物体的声源区域
- 交互编辑:最终支持通过自然语言指令实时调整
基于AudioCoT数据集的进阶训练
研究团队开发了全面的AudioCoT多模态数据集用于训练ThinkSound,包含:
- 2,531.8小时高品质音频样本
- 整合VGGSound与AudioSet内容资源
- 多阶段质量验证流程
- 专项物体级与指令级样本
这种强效训练使模型能够处理复杂指令,例如"提取猫头鹰叫声同时规避风声干扰"。
卓越的性能指标
实验数据彰显ThinkSound的优势:
- 在VGGSound测试集上比主流方法提升15%
- 在MovieGen Audio Bench测试集上超越Meta同类模型 模型代码与预训练权重现已开放获取:
- GitHub: https://github.com/FunAudioLLM/ThinkSound
- HuggingFace: https://huggingface.co/spaces/FunAudioLLM/ThinkSound
- ModelScope: https://www.modelscope.cn/studios/iic/ThinkSound
未来应用与行业影响
阿里巴巴团队计划扩展ThinkSound的能力以支持:
- 复杂声学环境理解
- 游戏开发与虚拟现实应用 行业专家预测该技术将:
- 变革影视音效制作流程
- 重塑人机交互边界
- 加速创作者经济创新
核心要点:
- 首个具备思维链推理的音频生成模型
- 三阶段流程确保精准的声画同步
- 基于2,500+小时专项AudioCoT数据集训练
- 以显著优势超越竞争对手
- 开源特性促进广泛采用