OpenAI增强ChatGPT安全性,抵御隐蔽提示攻击
OpenAI强化ChatGPT防御机制应对狡猾黑客
ChatGPT变得更难被欺骗了。OpenAI本周宣布对其AI安全系统进行重大升级,专门设计用于阻止日益复杂的提示注入攻击——这种数字手段相当于针对人工智能的社会工程骗局。
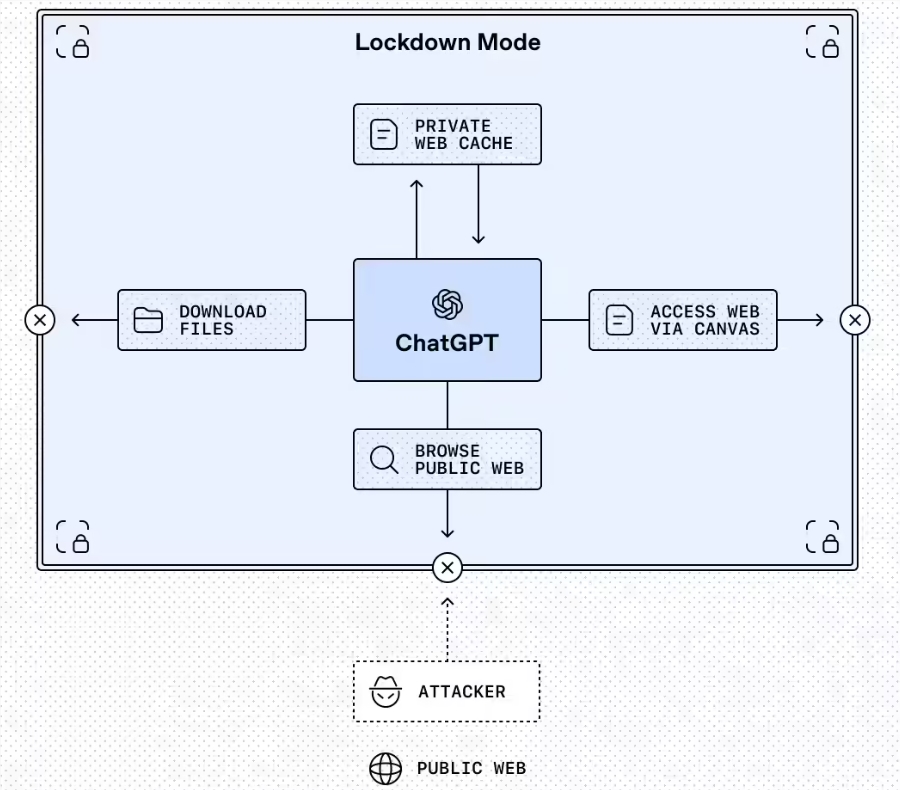
漏洞封锁模式
最突出的功能是锁定模式,这是当前面向企业和教育版本的可选设置。可以将其想象成ChatGPT在进入可疑网络环境前穿戴的盔甲。激活后,它将严格限制AI与外部系统的交互:
- 网页浏览仅限于缓存内容
- 自动禁用缺乏可靠安全保障的功能
- 管理员可精细调控哪些外部应用保持可访问状态
"我们让机构能更严格地控制风险暴露程度,"OpenAI发言人解释道,"锁定模式并非用于日常聊天——它是高风险专业环境的数字护甲。"
该模式随增强型仪表盘控制功能同步推出,IT团队可:
- 创建自定义权限角色
- 通过合规API日志监控使用情况
- 准备详细的监管审计
明确风险标签
第二项重大变化是在ChatGPT、Atlas和Codex产品中引入标准化"高风险"标签。当用户启用无限制网络访问等潜在危险功能时,这些鲜红色警示就会显现。
这些标签不仅高呼"危险!"——还提供实用指导:
- 涉及的具体风险
- 推荐的缓解策略
- 理想的使用场景
使用Codex的开发者在启用可能暴露敏感数据的网络功能时,会特别受益于这些警告。
当下重要性
提示注入攻击已成为AI最阴险的威胁之一。狡猾的黑客可操纵聊天机器人:
- 泄露机密信息
- 执行未授权命令
- 绕过道德防护机制
新防护措施表明:虽然联网AI具有巨大实用性,但这些优势伴随着需要谨慎防护的真实风险。
展望未来,OpenAI计划数月内向消费者版本推出锁定模式——尽管大多数家庭用户可能不需要其最严格的设置。
关键要点:
- 锁定模式限制企业/教育用户的高风险外部交互
- 高风险标签清晰警示潜在危险功能
- 两项功能均建立在现有沙盒和URL保护系统基础上
- 消费者版本更新预计今年晚些时候推出