微软的微型动力源:5亿参数AI实现近乎即时的语音合成
微软以紧凑型语音AI突破速度壁垒
在实时语音技术的突破中,微软新款VibeVoice-Realtime-0.5B证明了'更大并不总是更好'。这个精简的5亿参数模型生成语音的速度如此之快——约300毫秒内开始响应——以至于开发者称之为'预期效应'。听众在心理上完成自己的句子前就开始听到回复。
闪电速度下的自然语音
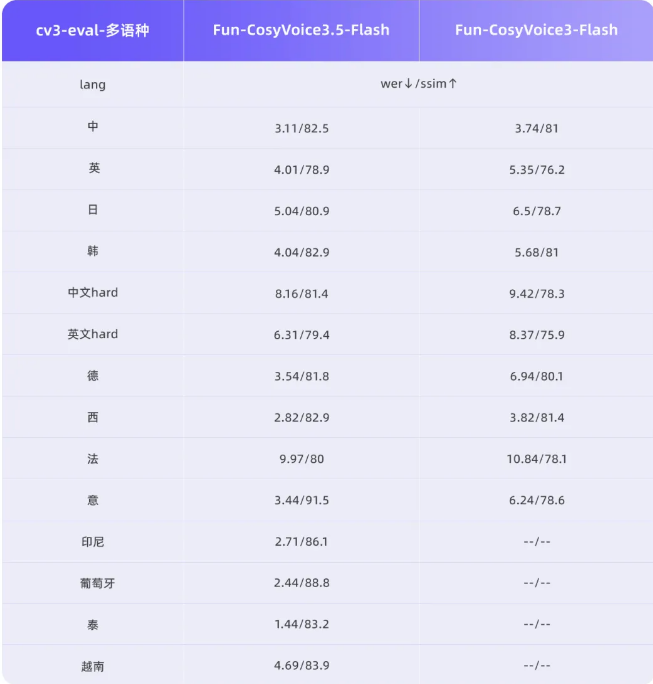
其秘诀在于优化的架构设计,在不牺牲质量的前提下优先考虑响应能力。虽然英语表现稍强,但这个双语模型在中文上也保持了出色的流畅度。与早期系统在处理长段落时磕磕绊绊不同,VibeVoice能持续90分钟不间断语音而不出现可察觉的故障或音调不一致。
'我们跨越了一个重要门槛,合成语音现在能跟上人类对话的节奏了,'微软项目负责人解释道。'现在的延迟时间比大多数人句子间的自然停顿还要短。'
多声部对话栩栩如生
该模型真正出彩之处在于处理交互场景:
- 同时支持多达四种独特声线
- 在延长对话中保持独特的声纹特征
- 完美适用于播客模拟或虚拟访谈形式
系统对每个说话者节奏和语调模式的追踪如此逼真,以至于测试者报告称在多角色交流时会忘记自己听到的不是真人参与者。
内在的情感智能
除了技术规格外,VibeVoice的独特之处在于其细腻的情感解读能力:
- 检测愤怒、兴奋或歉意等文本线索
- 相应调整音高和节奏
- 甚至能捕捉犹豫停顿或强调重音等微妙变化
结果如何?合成声音听起来真正投入其中而非机械复述文字。
小巧体积,巨大潜力
仅0.5B参数——按当今标准堪称微小——该模型提供了实用优势:
| 特性 | 优势 |
|---|
微软计划将其集成到智能助手、呼叫中心系统和辅助工具等即时响应至关重要的场景中。
关键要点:
- 300毫秒响应时间——快于人类停顿时长
- 90分钟独白期间保持声音一致性
- 处理四路对话且角色声线分明
- 从文本线索解读情感语境
- 轻量设计支持端侧部署
The model is now available on Hugging Face for developers to experiment with.